



Une station de travail pour classer, cartographier et analyser l'information bibliographique dans une perspective de veille scientifique et technique
Luc GRIVEL, Claire FRANÇOIS
 |
Cet article développe dans sa première partie les
caractéristiques méthodologiques et technologiques d'une station
d'analyse de l'information scientifique et technique fonctionnant sous UNIX et
basée sur la norme SGML. Celle-ci permet de classer et
représenter graphiquement d'énormes quantités
d'information bibliographique en s'appuyant sur deux méthodes permettant
de construire des cartes thématiques : une méthode
éprouvée, les mots associés, et une autre plus
récente associant une technique de classification, les K-means axiales,
à une technique d'analyse factorielle courante : l'Analyse en
Composantes Principales (ACP). Les deux méthodes sont
présentées en détail et comparées d'un point de vue
théorique. Il en ressort qu'il existe une grande symétrie entre
les deux processus, expliquant les accords observés
expérimentalement entre les résultats des deux méthodes. En abordant dans la deuxième partie le problème de la qualification des résultats afin de limiter les risques d'erreurs lors de leur interprétation, nous exposons sur un exemple une démarche d'analyse et mettons l'accent sur la possibilité de mesurer les accords entre les résultats des deux méthodes d'analyse par des indicateurs globaux. Il reste cependant que les méthodes offrent des représentations différentes : classes de mots-clés structurées par les relations de cooccurrences dans un cas, classes de mots-clés floues et recouvrantes représentées par des demi-axes dans l'autre ; cartes thématiques fournissant des informations de natures différentes : indicateurs structurels et visualisation des réseaux locaux dans un cas, oppositions des thèmes selon deux axes principaux dans l'autre cas. Une richesse au niveau des représentations qui font de ce poste de travail un véritable instrument d'exploitation de l'information bibliographique dans une perspective de veille scientifique. En conclusion, nous présentons les évolutions envisagées pour cette station.
|
 Introduction
Introduction
Dans cette perspective, nous présentons ici une station d'analyse de l'information scientifique et technique développée dans le cadre du programme de recherche en infométrie de l'INIST [1]/CNRS [2]. D'un point de vue fonctionnel, elle doit non seulement fournir tous les indicateurs numériques usuellement mis en oeuvre pour prendre la mesure de l'information bibliographique, mais également proposer des représentations du contenu de la production scientifique [3]. Elle automatise l'élaboration des distributions bibliométriques (statistiques unidimensionnelles sur les champs bibliographiques), et elle supporte deux méthodes permettant de construire des cartes thématiques : une méthode éprouvée, les mots associés [Callon et al 1983]), et une autre plus récente associant une technique de classification, les K-means axiales [Lelu 1990 et 1993] à une technique d'analyse factorielle courante : l'Analyse en Composantes Principales (ACP).
Notre objectif est de classer et représenter d'énormes quantités d'information bibliographique afin d'en extraire des synthèses élaborées utilisables pour effectuer une veille scientifique (données chiffrées caractérisant un ensemble de références bibliographiques, hypertextes thématiques, documents de synthèse tels que des cartes de l'information scientifique et technique).
La première partie de cet article décrit les méthodes
mises en oeuvre pour représenter le contenu de l'information et montre
leur spécificité et leur complémentarité. Nous y
exposons également nos choix technologiques, puis nous décrivons
l'objet technique réalisé : une chaîne de traitement
infométrique sous Unix, basée sur la norme SGML.
La deuxième partie est consacrée à l'analyse des
résultats. Nous abordons ici le problème de la qualification des
résultats afin de limiter les risques d'erreurs lors de leur
interprétation. L'analyse des distributions bibliométriques n'est
qu'esquissée. Elle ne présente, à notre avis, pas de
difficultés majeures, puisqu'il est possible de s'appuyer sur des lois
qui décrivent leur comportement. Par contre, l'exploitation des
résultats de méthodes d'analyse de données demande
quelques précautions car il ne faut pas oublier qu'elles
procèdent par réduction de données. Nous exposons donc une
démarche d'analyse basée sur l'observation d'indicateurs
permettant d'apprécier la qualité des résultats produits
par notre station de travail. Pour illustrer cette démarche, nous
utilisons les résultats du traitement d'un petit corpus [4] de références bibliographiques
(quelques centaines de documents).
En conclusion, nous effectuons un bilan comparatif des deux méthodes et
décrivons les évolutions futures de la station de travail.
2
- Choix méthodologiques et technologiques
 2.1
- Méthodes mises en oeuvre
2.1
- Méthodes mises en oeuvre
Si les méthodes à mettre en oeuvre pour obtenir les distributions bibliométriques sont relativement bien standardisées et banalisées, il n'en est pas de même pour la représentation de l'IST. C'est pourquoi nous nous contenterons de développer ce deuxième aspect.
Les indicateurs que nous utilisons pour représenter le contenu de
l'information sont les cartes thématiques. D'une manière
générale, nous définissons une carte thématique
comme étant une représentation de la topologie des relations
entre des disciplines ou des thèmes de recherche, telle qu'elles sont
matérialisées sous la forme de données bibliographiques.
Pour construire ces cartes, notre choix s'est porté en priorité
sur deux méthodes d'analyse de corpus documentaire déjà
décrites dans la littérature : la méthode des mots
associés implémentée par le logiciel SDOC, et une
méthode associant les K-means axiales à une Analyse en
Composantes Principales (ACP) implémentée par le logiciel
NEURODOC.
Pour des raisons historiques, ces méthodes sont bien connues de notre
programme de recherche. Nous bénéficions de l'expérience
acquise par le SERPIA [5], département
de R & D du CDST [6] avant la fondation de
l'INIST. En effet, la méthode des mots associés est le fruit
d'une collaboration entre le Centre de Sociologie de l'Innovation de l'Ecole
des Mines de Paris et le CDST [Callon et al 1983]. Le logiciel
développé à l'époque s'appelle LEXIMAPPE. Quant
à la méthode basée sur les K-means axiales et l'ACP, elle
a été mise au point par A. Lelu, alors qu'il était membre
du SERPIA [Lelu 1990].
Ces deux méthodes utilisent les mots-clés qui indexent les
références bibliographiques pour construire les structures
thématiques "enfouies" dans les bases de données. Pour
schématiser, elles trouvent les thèmes abordés et classent
les documents selon ces thèmes. Ceux-ci sont ensuite disposés sur
un espace à 2 dimensions : "carte thématique".
Cette méthode considère les mots-clés comme des
indicateurs de connaissance (contenu des documents indexés) et se base
sur leurs cooccurrences pour mettre en évidence la structure de leurs
relations (clusters [7]). L'idée de
cooccurrence est essentielle. En effet, si on considère que deux
documents sont proches parce qu'ils sont indexés par des
mots-clés similaires, alors deux mots-clés figurant ensemble dans
un grand nombre de documents seront considérés comme proches.
Cependant, la cooccurrence ne permet pas à elle seule de mesurer la
force des associations entre mots-clés (leur proximité), car elle
avantage les mots-clés de haute fréquence par rapport à
ceux de basse fréquence. L'emploi d'un indice statistique
approprié permet de normaliser la mesure de l'association entre deux
mots-clés. En pratique, nous utilisons le plus souvent l'indice
d'Équivalence dont les valeurs varient entre 0 et 1 :
A partir des mesures de proximité entre les mots, un algorithme de classification hiérarchique construit des groupes de mots proches les uns des autres (clusters) n'excédant pas une taille maximale (nombre de mots) fixée par l'utilisateur. Ainsi la figure 1 montre deux clusters C1 et C2 contenant respectivement : les mots-clés A, B, C, D, E d'une part ; F, G, H, I d'autre part. Un cluster est donc constitué de mots associés les uns aux autres (associations internes). Les clusters peuvent avoir des relations entre eux. Ceci se produit lorsqu'il existe une association entre 2 mots-clés appartenant à 2 clusters différents (association externe) et que la taille du nouveau cluster qui aurait résulté de la réunion de ces 2 clusters dépasse la taille maximum définie par l'utilisateur. Ainsi C1 et C2 sont reliés par une association externe entre C et F car la taille des clusters ne peut excéder un maximum de cinq mots dans l'exemple présenté.
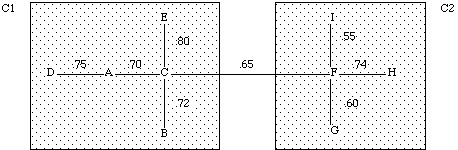
Figure 1 -- deux clusters C1 et C2 de 5 mots maximum
Après le processus de classification des mots-clés, les documents sont affectés aux clusters de la manière suivante : un document est associé à un cluster, si dans sa liste de mots-clés, il existe au moins un couple de mots-clés qui pourrait constituer une association interne ou externe du cluster.
La classification est principalement paramétrée par le nombre
maximal de mots pouvant constituer un cluster. C'est une variante de la
procédure statistique habituelle qui consisterait à utiliser un
seuil fixe (une "distance limite" à partir de laquelle aucune
agrégation n'est plus effectuée). C'est un moyen pratique pour
moduler la coupure dans l'arbre de classification (dendrogramme). En
conséquence du critère de taille maximale, les classes
résultantes sont très hétérogènes en
densité. La première classe obtenue sera constituée des
mots-clés les plus fortement liés alors que la dernière
sera très lâche, restituant en cela la structure du réseau
d'associations. On peut également limiter le nombre d'associations intra
ou inter-clusters dans un souci de lisibilité. Les autres
paramètres de la méthode se situent en amont de la classification
(filtrages au niveau du vocabulaire d'indexation : fréquence des
mots-clés, cooccurrence, ...), ou en aval (filtrage des clusters par le
nombre de mots ou de documents qu'ils comportent, ...).
Cartographie
Des indicateurs structurels sont ensuite calculés. Ce sont la densité (valeur moyenne des associations entre mots-clés formant un cluster ou associations internes) et la centralité (valeur moyenne des associations entre les mots qui le constituent et les mots d'autres clusters ou associations externes). Ces valeurs sont ensuite utilisées pour positionner les clusters sur une carte. On peut ainsi repérer les thèmes (ou clusters) les mieux structurés du point de vue de leur densité (ou cohésion), les mieux rattachés au réseau (centralité). Sur une telle carte, la proximité entre deux thèmes indique qu'ils sont structurellement proches, mais leur contenu sémantique ne sont généralement pas voisins. Les auteurs de la méthode des mots associés appellent ce type de carte "diagramme stratégique" [Callon et al.1993, p. 86]. Ils l'utilisent pour évaluer l'intérêt stratégique des thèmes. Leur objectif est avant tout sociologique : étude des dimensions sociales et organisationnelles de la science [Courtial 90], [Turner 94]. Nous utilisons la même méthode de construction de cartes avec un autre objectif : permettre à un utilisateur d'appréhender globalement et localement le contenu d'un corpus bibliographique. Ainsi la figure 6 présentée dans la deuxième partie est un exemple de carte affichant les relations qu'un thème entretient avec d'autres thèmes, dans le domaine des systèmes experts et intelligence artificielle.
Cette méthode considère l'ensemble des références bibliographiques comme un nuage de points plongé dans un espace géométrique où chaque dimension correspond à un mot-clé. Elle est caractérisée par une représentation des classes par des vecteurs pointant vers les zones de forte densité du nuage.
La figure 2 montre l'exemple d'un corpus de documents indexés par les 3 mots-clés x1, x2, et x3. Ces mots-clés définissent l'espace R3, un document i indexé par les mots-clés x1 et x2 aura les coordonnées suivantes : (1, 1, 0)

Figure 2 -- Représentation d'un corpus documentaire
dans un espace
géométrique R3.

Figure 3 -- Partition définitive des documents dans les classes.
Sur la figure 3 :
Sur la figure 3, nous observons également que la projection du document ii sur l'axe Ak (yii(k)) est supérieure à celle du document i (yi(k)). Nous pouvons donc ordonner les documents appartenant à une classe selon la valeur de leur projection sur l'axe représentant la classe. Cet ordre correspond à un ordre de "typicité" décroissant des documents par rapport au type idéal de la classe qui est un document fictif positionné exactement sur l'axe de la classe dans l'espace géométrique.
En utilisant les valeurs des composantes du vecteur unitaire des classes, nous
pouvons définir de la même façon une partition des
mots-clés du corpus documentaire. Comme pour les documents, la partition
ainsi établie admet des classes recouvrantes, un mot-clé peut
appartenir à plusieurs classes, et les mots-clés sont
ordonnés selon un ordre de "typicité" décroissant par
rapport au type idéal de la classe. La pondération
utilisée pour calculer la valeur de "typicité" permet de faire
ressortir les mots-clés spécifiques (ou typiques) de la classe,
c'est-à-dire fréquents dans cette classe et rares dans l'ensemble
des documents.
Cet algorithme, paramétré par le nombre maximal de classes
désiré et le seuil des coordonnées des documents et des
mots-clés sur les axes, permet donc de construire des classes d'un type
particulier :
Cartographie par Analyse en Composantes Principales
Une classe de documents correspond à un thème, sous-ensemble homogène de l'information contenue dans le corpus documentaire étudié. Une Analyse en Composantes Principales de l'ensemble des classes dans l'espace géométrique permet de déterminer un plan déformant le moins possible le nuage de points de ces classes. Tous les points de ce nuage sont ensuite projetés sur ce plan, constituant ainsi la carte globale des thèmes. Sur cette carte, deux thèmes éloignés représentent des classes dissemblables quant aux mots-clés les définissant. Sur de telles cartes, on peut repérer en particulier des thèmes "exceptionnels", ou des sous-groupes de thèmes.
A. Lelu a démontré que les 2 méthodes sont symétriques l'une de l'autre [page 93, Lelu 93].
En résumé, les K-means Axiales effectuent une classification des lignes dans un tableau documents x descripteurs, tandis que les Mots Associés effectuent une classification des colonnes de ce même tableau, en utilisant le même indice de similarité [9].
Or, dans nos applications, les tableaux de données sont très
creux et peuvent se segmenter le plus souvent en blocs de lignes et
de colonnes quasi-indépendants les uns des autres. Dans ce cas limite,
la classification sur les lignes et la classification sur les colonnes
aboutissent à détecter les mêmes blocs dans le
tableau.
En effet, dans nos expérimentations, nous n'avons pas relevé de contradictions entre les résultats des deux méthodes sur un même fichier de données. En les paramétrant de façon à obtenir un nombre identique de classes à partir d'un même fichier de données, il est courant d'observer entre 60 et 80 % de classes similaires. Les deux méthodes détectent sensiblement les mêmes blocs. Leur emploi sur un même fichier permet donc d'obtenir des représentations différentes des classes que nous récapitulons ici :
2.2
- Technologie informatique
Nos choix ont visé :
Pour atteindre le premier objectif, nous avons utilisé les techniques du Génie Logiciel : modularité par décomposition en programmes indépendants, adoption de standards. La station de travail a été conçue comme un outil modulaire doté d'un ensemble de fonctionnalités qui peuvent être mises en oeuvre selon les besoins de l'analyse.
Pour atteindre le deuxième objectif, nous avons estimé qu'il
fallait avant tout banaliser et standardiser le processus de traitement de
l'information en l'automatisant.
La nature textuelle des données à analyser, la diversité de leur structure, le nombre de champs différents à traiter pour mener à bien une étude infométrique, nous ont amenés à adopter la norme SGML [10] pour la description de la structure logique de tous les documents manipulés par les outils de la station. Les avantages immédiats de ce choix sont : distinction nette entre contenant et contenu, codage unique des caractères accentués, règles de balisage, existence d'outils sur le marché, ...
A titre d'exemple, une notice bibliographique provenant d'un serveur ou d'un
CD-Rom se présente généralement comme suit :
La structure logique d'une telle information est très simple : une suite de champs repérés par un identifieur. Il est alors facile de définir les règles lexicales qui permettent d'identifier le début, la fin d'une notice, le début ou la fin d'un champ à l'intérieur de la notice de manière à la transformer en document SGML.
En SGML, chaque élément structurel est repéré par
une balise de début : <identifieur de l'élément> et
une balise de fin : </identifieur de l'élément>. La notice
ci-dessus peut d'écrire en format SGML :
Une fois que toutes les données sont décrites dans ce format pivot, il est plus facile de concevoir des outils génériques utilisant les propriétés du balisage SGML. La plupart des traitements sur de tels documents se réduisent à associer des actions à un élément de la grammaire et, dans bien des cas, travailler au niveau lexicographique suffit. Ces caractéristiques nous ont conduits à développer une boîte à outils (appelée ILIB) basée sur SGML et sur UNIX [Ducloy et al 1991]. En effet des programmes générés par Lex et des outils UNIX tels que Awk sont bien adaptés pour extraire de l'information "à la volée" sur un flot de données structurées, puis la traiter.
La station de travail est ainsi constituée de modules
indépendants de traitement de l'information qui communiquent entre eux
par flot de données en s'appuyant sur le mécanisme de pipe
d'UNIX. En collaboration avec H. Millerand et J. Kasprzak du service
étude de la direction informatique INIST, nous avons effectué des
tests d'applications de SDOC et NEURODOC sur de gros volumes de données (transcripts dans le guide technique de SDOC et NEURODOC). A titre d'exemple,
le traitement de 16 000 références bibliographiques par l'un ou
l'autre des outils prend environ dix heures sur une machine déjà
ancienne, Sun Sparc 1, avec 16 Mo de mémoire vive. Il faut noter que ce
n'est pas la phase de classification elle-même qui est longue, mais la
phase de documentation des classes (libellés des mots-clés,
titres, sources, auteurs, ...) ; celle-ci prend plus de la moitié du
temps d'exécution. Elle sera optimisée ultérieurement.
Dans le souci de faciliter l'utilisation de cette station de travail, nous avons défini des scénarii d'analyse standards. Ces derniers sont matérialisés par des "fichiers de paramètres standards" où sont définis les paramètres de l'analyse (directement dépendants de la méthode choisie) et les différentes éditions ou mises en forme de résultats souhaitées. L'utilisateur peut donc éditer un fichier de paramètres standard, le modifier, l'enregistrer sous un autre nom, puis demander l'exécution de telle ou telle phase de traitement à partir du nouveau fichier de paramètres.
Nous avons apporté un soin particulier à la mise en forme des
résultats avec comme objectif d'obtenir des représentations
lisibles et combinables favorisant l'intuition et les rapprochements
d'idées. Pour cela, nous nous sommes appuyés sur trois techniques :
2.3
- La chaîne de traitement infométrique
La figure 4 présente le déroulement général d'une
application scientométrique.
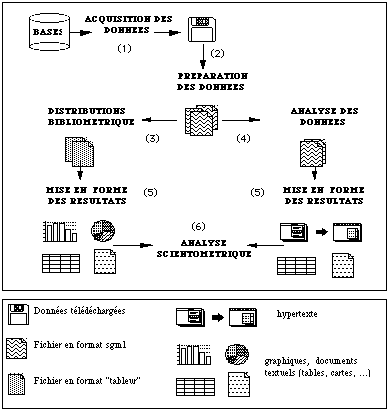
Figure 4 -- La chaîne de traitement infométrique.
Le schéma de traitement proposé comprend 6 phases successives :
Les phases 2 à 5 sont automatisées et seront décrites dans ce paragraphe. La phase d'acquisition des données (1) est manuelle et dépend des données à étudier; elle ne sera pas détaillée ici. L' analyse scientométrique des résultats (phase 6) est manuelle; elle est traitée dans la deuxième partie de l'article.
Cette phase permet de normaliser la collection de documents (reformatage) et de générer les données nécessaires aux phases 3 et 4, à savoir :
Cette phase est paramétrée par le nom des champs bibliographiques pour lesquels la création d'index est effectuée ainsi que par les séparateurs de forme. Les index sont également des documents SGML.
Cette phase a pour objectif d'établir les distributions des champs à étudier. Outre des informations de nature quantitative sur les données, elle fournit des indicateurs utilisés pour le paramétrage de la classification. Elle est également paramétrée par le nom des champs sur lesquels les comptages sont effectués.
Cette phase permet la création des classes de mots-clés et de documents en format SGML. Elle est indépendante du format initial des documents, car elle prend en entrée les données normalisées obtenues par la phase 2.
Deux logiciels sont disponibles à ce jour :
Les traitements de SDOC s'effectuent en 4 étapes : 1) calcul des cooccurrences de mots-clés et mesure de la force d'association des paires de mots-clés, 2) classification : regroupement des mots-clés en clusters, 3) calcul des coordonnées géographiques des clusters, 4) affectation aux clusters des documents et des informations relatives à ceux-ci (titre, auteurs, sources).
Les traitements de NEURODOC s'effectuent en 3 étapes : 1) calcul des
classes de mots-clés et de documents par la méthode des K-means
axiales, 2) calcul des coordonnées géographiques des classes sur
un plan par une Analyse en Composantes Principales, 3) documentation des
classes, c'est-à-dire addition du libellé des mots-clés,
du titre des documents, des auteurs et des sources associés.
Cette phase permet à l'utilisateur de visualiser les résultats des phases 3 et 4. Les représentations générées sont les instruments de travail de l'analyse scientométrique (phase 6).
3
- Analyse scientométrique des résultats
3.1
- Exploitation des distributions bibliométriques
A partir des différentes distributions, plusieurs types d'observations peuvent être effectuées. Pour un domaine donné, on peut ainsi quantifier sa magnitude (nombre d'articles, nombre de revues), son actualité (selon la date de publication), sa localisation (selon le pays d'édition des revues scientifiques), l'importance des périodiques scientifiques (selon le nombre d'articles dont ils sont la source au cours d'une période déterminée), la localisation des auteurs (selon leur appartenance institutionnelle) et son vocabulaire d'indexation.
Tous ces éléments seront également utilisés pour
orienter une analyse approfondie d'un domaine particulier. Ils permettront de
définir un corpus de références bibliographiques
homogène et pertinent, sur lequel les méthodes d'analyse des
données peuvent être appliquées. Par exemple, on peut
utiliser la loi de Bradford pour focaliser son attention sur les revues les
plus "productives" en termes d'articles recueillis dans le corpus, ainsi que la
loi de Zipf pour déterminer le vocabulaire d'indexation pertinent pour
l'analyse. Cette loi nous permet de séparer le vocabulaire d'indexation
en trois groupes :
C'est donc le second ensemble de mots-clés qui fournit l'information la
plus intéressante et qui est traité par les méthodes
d'analyse de données.
3.2
- Exploitation des résultats des méthodes d'analyse de
données
Pour chaque méthode, nous décrirons la structure des classes obtenues, puis le protocole d'interprétation des classes et cartes. Celui-ci est basé sur l'observation d'indicateurs générés automatiquement permettant d'apprécier la qualité de la classification obtenue d'un point de vue global puis local à chaque classe. Nous suivrons un plan rigoureusement parallèle pour permettre une comparaison entre les deux méthodes. Nous utiliserons les résultats du traitement d'un corpus de références extraites de la base PASCAL, au début de l'année 1990, dans le domaine des Sciences de l'ingénieur : "Intelligence Artificielle : systèmes experts". Ce corpus comprend 316 références, il est indexé par 955 mots-clés dont 665 de fréquence 1 (soit 70% du vocabulaire d'indexation).
La première étape des deux analyses présentées ci-dessous a consisté en une sélection du vocabulaire d'indexation en se basant sur la loi de Zipf :
Le résultat de la classification est une partition des mots-clés en classes structurées mais disjointes (clusters), même si les clusters peuvent entretenir des relations avec d'autres clusters. Un cluster représente un thème trouvé dans un ensemble de documents.
La figure 5 décrit l'un des 21 clusters obtenus par SDOC sur ce corpus en limitant la taille des clusters à 10 mots et en fixant une cooccurrence minimale des mots-clés à 2.

Figure 5 -- Exemple de thème obtenu avec SDOC : "Recherche
documentaire".
Un cluster est composé de :
La liste de mots-clés regroupe des mots qui sont proches les uns des autres. Nous distinguons les mots-clés internes (qui apparaissent dans les associations internes) des mots-clés externes (qui apparaissent seulement dans les associations externes car ils ont été rejetés de ce cluster à cause du critère de taille maximal des clusters). Ainsi, sur la figure, les mots-clés figurant dans les associations internes constituent les mots-clés internes du cluster Recherche documentaire et les mots-clés situés à droite dans les associations externes constituent les mots-clés externes du cluster. Par exemple Interface dans Recherche documentaire - Interface sera l'un de ses mots-clés externes. Les mots-clés sont triés selon leur nombre d'apparitions dans les associations internes et externes du cluster.
La liste d'associations internes décrit la force des associations des
mots qui définissent la structure interne des clusters. Par exemple,
l'association Analyse sémantique - Analyse syntaxique du cluster
Recherche documentaire a un poids de 0.27. Plus la valeur de l'association est
forte, plus les mots sont fortement associés.
La liste d'associations externes décrit les associations existantes entre
les mots d'un cluster et les mots d'autres clusters. Dans l'exemple de la
figure 5, l'association Recherche documentaire - Interface relie les clusters
Recherche documentaire et Langage naturel. Le nombre d'associations externes
peut être limité aux N plus fortes. Dans ce cas, les associations
externes ne sont pas nécessairement bi-directionnelles. Dans le cas
présent, nous l'avons limité aux 10 plus fortes.
&Étiquetage des clusters : le choix d'un terme représentatif pour
nommer le cluster est basé sur une heuristique. Nous choisissons le
terme de la liste des mots-clés internes qui apparaît le plus
grand nombre de fois dans les associations internes et externes. Par exemple,
le programme SDOC proposera le mot-clé Recherche documentaire pour
désigner le cluster de la figure 5. Le nom proposé est
satisfaisant dans plus de 90% des cas.
La liste des documents affectés à un cluster : elle est obtenue
après exécution de la classification. C'est la liste des
documents qui ont contribué à la formation de ce cluster par la
présence dans leur indexation de couples de mots-clés qui
pourraient constituer une association interne ou externe du cluster. Un
document peut donc figurer dans plusieurs clusters. Un document ne figurant que
dans un seul cluster est appelé document propre au cluster. Les
documents sont triés selon l'importance de leur contribution à
l'élaboration du cluster. A partir des documents sont extraits le titre,
les auteurs et la source pour compléter la description du cluster.
Des indicateurs globaux permettent d'apprécier la validité du paramétrage et caractérisent la partition.
Un tableau résumant les caractéristiques structurelles des clusters permet de les catégoriser et d'apprécier la répartition des documents dans les clusters.

Tableau 1-- Exemple de tableau des caractéristiques des clusters.
[1] : Seuil de saturation,
[2] : Densité,
[3] : Centralité,
[4] : Nombre de mots-clés internes,
[5] : Nombre de mots-clés externes,
[6] : Nombre d'associations internes,
[7] : Nombre d'associations externes avec d'autres clusters,
[8] : Nombre de citations du cluster par d'autres clusters,
[9] : Nombre de documents définissant le cluster,
[10] : Nombre de documents propres au cluster.
Le seuil de saturation d'un cluster [1] est la valeur de la dernière association interne ajoutée avant sa saturation, c'est-à-dire lorsqu'il ne peut plus grandir en taille. Trier le tableau selon cette valeur permet de connaître l'ordre dans lequel les clusters se sont figés. Ainsi, le cluster Langage naturel s'est stabilisé après le cluster Recherche documentaire.
La densité [2] d'un cluster est la moyenne des associations internes du
cluster. C'est un indicateur de sa cohésion, son
homogénéité. L'examen de sa taille [4] et de son nombre
d'associations internes [6] permet d'avoir une idée plus précise
de cette cohésion. La densité de Recherche documentaire est
presque similaire à celle de Langage naturel, mais le rapport "nombre de
mots qui le constituent" sur "le nombre de connections entre ces mots" est plus
faible, indiquant une connectivité plus importante. On peut dire que
Recherche documentaire a une cohésion plus forte que Langage naturel. La
somme des valeurs de [4] donne le nombre de mots-clés gardés dans
les clusters.
La centralité d'un cluster [3] est la valeur moyenne des associations
externes. Le nombre de citation [8] d'un cluster indique le nombre de fois
qu'un cluster est cité par les autres clusters via leurs associations
externes. On considère que les colonnes [3], [5], [7] and [8]
caractérisent les associations externes d'un cluster et permettent
d'apprécier son rattachement au réseau. Ainsi les 2 clusters
Recherche documentaire et Langage naturel ont de nombreux liens avec les autres
clusters du réseau, tandis que Revêtement métallique est
particulièrement isolé. Le cas de Industrie bâtiment est un
petit peu plus complexe, car il n'a pas d'associations externes, mais il est
cité 11 fois. La navigation hypertexte permet de lever
immédiatement ce mystère en facilitant l'accès à la
description des clusters. En fait, il existe un thème nommé
Conception assistée traitant des applications de l'IA dans l'industrie
naval qui fait neuf fois référence à Industrie
bâtiment à travers le terme Conception assistée. On a donc
en réalité deux thèmes autonomes : Industrie
bâtiment et un thème qu'on peut appeler Industrie naval, aux
vocabulaires très spécifiques reliés par un terme plus
générique de fréquence plus élevée
Conception assistée. Le tri du tableau complet des clusters par
centralité permet de situer la force de ces liens qui dans le cas
présent était relativement élevée pour Recherche
documentaire (dans le premier tiers d'un tableau de 21 clusters).
Les colonnes [9] et [10] permettent d'apprécier la répartition
des documents dans les clusters. Comme un document peut appartenir à
plusieurs clusters, le nombre total de documents classés dans un cluster
donné [9] est distinct du nombre de documents propres au cluster [10].
Aussi la somme des valeurs de la colonne [9] donne le nombre d'occurrences de
documents dans les clusters. La somme des valeurs de la colonne [10] donne le
nombre de documents qui ne figurent que dans un seul cluster. Le rapport des
colonnes [9] et [10] donne le pourcentage de documents propres à un
cluster.
Nous utilisons une catégorisation des clusters décrite dans
[Courtial 1990, page 100] pour définir un plan de lecture des clusters.
Un cluster est dit principal si son seuil de saturation [1] est plus
élevé que celui de ces clusters associés ou clusters
externes. L'intensité de ses associations externes [3] est
généralement inférieure à son seuil de saturation.
Les clusters associés sont appelés clusters secondaires.
Ils sont l'extension naturelle du cluster principal. Ainsi Recherche
documentaire est un exemple de cluster principal avec comme cluster secondaire
associé Langage naturel qui par ailleurs joue un rôle de cluster
principal vis-à-vis de processus acquisition. Par cette méthode
de lecture, le découpage en classes de tailles fixes ne change pas les
résultats que l'on cherche à mettre en évidence.
Dans une lecture des clusters en vue d'une analyse, nous privilégions les clusters principaux entretenant de nombreuses relations avec d'autres clusters, en vue d'appréhender le plus rapidement possible les principaux noeuds thématiques du réseau.
Pour établir ce plan de lecture, le tableau des caractéristiques
des clusters ne suffit pas. Il faut également utiliser la description
complète des clusters, en particulier étudier
précisément leurs associations externes pour les situer les uns
par rapport aux autres, comme on l'a vu par exemple dans le cas du cluster
Industrie Bâtiment.
Les cartes fournissent une synthèse visuelle de deux paramètres du tableau précédent : la densité et la centralité.
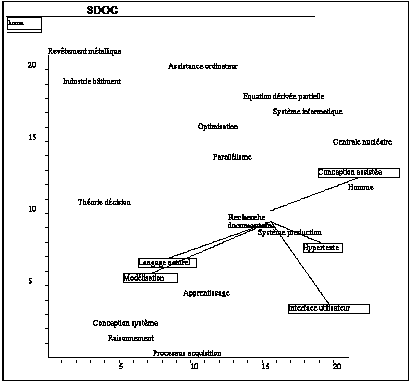
Figure 6 -- Exemple de carte thématique obtenue avec SDOC.
Nous resterons dans notre lecture de la carte au niveau d'une explication des résultats à partir du corpus étudié et de son vocabulaire d'indexation, sans faire d'interprétation sur l'intérêt stratégique des thèmes, type d'interprétation qui n'est pas de notre compétence. Puis nous montrerons que la visualisation des noms des clusters et la mise en évidence graphique des relations existant entre clusters peut permettre à un utilisateur de focaliser son attention sur un thème particulier et d'examiner des sous-réseaux du réseau global.
Dans l'exemple de la figure 6, on peut relever que les clusters Revêtement
métallique et Industrie bâtiment sont a priori isolés par
rapport au corpus (forte densité, faible centralité), ce qui est
confirmé par le nombre et l'examen des documents associés. Les
thèmes à forte densité se situent dans la partie haute de
la carte. Ce sont ici des applications de l'intelligence artificielle
(revêtement métallique, industrie bâtiment, systèmes
experts pour la résolution d'équation à
dérivées partielles, domaine documentaire, ...). Les documents en
question ont une indexation très spécifique pour décrire
le domaine d'application. Les thèmes situés au bas de la carte
ont une cohésion plus lâche. Ils correspondent ici en
général à des thèmes plus théoriques de
l'intelligence artificielle (raisonnement, modélisation, apprentissage,
etc.). Ils sont constitués de mots à fréquence
élevée et regroupent des ensembles de documents plus importants
que les précédents.
Si on se focalise sur un thème particulier, comme ici Recherche
documentaire, on peut examiner son réseau local. Étant
donné le corpus étudié, il n'est pas surprenant de trouver
de grands types d'application de l'IA à l'informatique documentaire tels
que les interfaces évoluées (hypertexte), les systèmes
d'analyse linguistique (langage naturel), les systèmes experts
fondés sur une représentation conceptuelle de documents (un
sous-thème présent dans le cluster modélisation). La
liaison avec Conception assistée exprime une relation plus
générale entre les mots-clés "traitement
automatisé" et "Conception assistée" sans qu'il y ait de rapports
directs avec la recherche documentaire. En effet le cluster "Conception
assistée" traite en fait d'applications de l'IA dans la construction
navale. La navigation hypertexte permet de suivre les associations
intéressantes et les cartes sont d'un grand secours pour éviter
de se perdre au cours de la consultation.
Le résultat de la classification est une partition des mots-clés et des documents en classes recouvrantes. Une classe ainsi définie correspond à un thème, sous-ensemble homogène de l'information contenue dans le corpus documentaire étudié.

Figure 7 -- Exemple de thème obtenu avec NEURODOC.
La figure 7 montre l'exemple de la classe ou du thème "Hypertexte" tel qu'il apparaît dans un des dispositifs hypertextes possibles (le logiciel Hypercard ® sur Macintosh ® [14]). Un thème est donc constitué de quatre listes : mots-clés, documents, auteurs et sources triées par ordre de pertinence décroissant par rapport au type idéal de la classe.
Une classe est nommée par le mot-clé de "typicité" [15] la plus forte par rapport au type idéal de la classe (cf § 2). Dans environ 20% des cas, la révision de ce nom par un expert peut être nécessaire.
Un mot-clé est représenté par son libellé et sa
valeur de "typicité" par rapport au thème. Les valeurs
de "typicité" des mots-clés permettent de distinguer les
mots-clés importants pour l'interprétation du thème, et
d'estimer la structure de la classe. En effet, nous observons deux types de
classes :
Un document est représenté par son titre et sa valeur de
"typicité" par rapport au thème. Les documents les plus pertinents
du thème sont en général les plus spécifiques au
thème. Les documents de pertinence moindre se retrouvent dans d'autres
thèmes, où ils sont d'ailleurs souvent mieux situés. Dans
le dispositif hypertexte, chaque titre de document donne accès à
la référence complète.
A partir des documents associés au thème, sont extraits, s'ils
existent, les auteurs et les sources de ces derniers. Les auteurs et les
sources sont affectés du poids du document correspondant. Si un auteur
ou une source est associé à plusieurs documents du thème,
les poids de ces derniers sont sommés. Les thèmes sont
complétés par la liste triée des auteurs et des sources.
Les listes des auteurs et des sources sont visualisables en
sélectionnant les mots "auteurs" et "sources" ; elles permettent de
connaître les équipes de scientifiques les plus importantes pour
un thème donné et les principales revues qui publient ces
articles.
La classification est effectuée par approximations successives ; aussi le récapitulatif du déroulement de la classification permet de vérifier la convergence du processus. Si la stabilisation n'a pas lieu, il peut être intéressant d'augmenter le nombre de classes pour créer des classes spécifiques aux documents oscillant entre deux classes.
Les indicateurs globaux permettant d'apprécier la qualité de la
partition obtenue sont :
Ces indicateurs montrent que la réduction des données est du même ordre de grandeur que celle obtenue avec SDOC. Pour l'outil NEURODOC, le taux de recouvrement est dépendant des paramètres de la classification (nombre de classes demandés et seuil des documents et mots-clés). Il est donc maîtrisable par l'utilisateur. Dans cet exemple, le taux de recouvrement est suffisamment faible pour considérer les documents et mots-clés conservés dans les classes comme pertinents.
Un tableau résumant les caractéristiques des classes permet d'apprécier la qualité de la répartition des documents dans les classes et de catégoriser ces dernières.
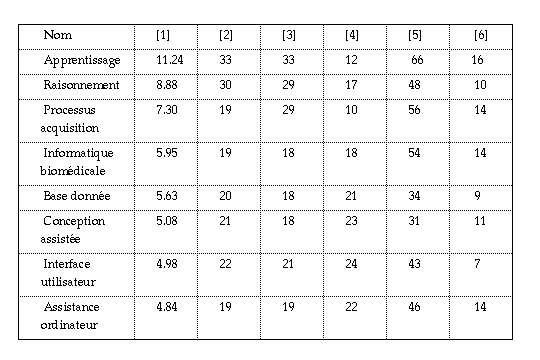
Tableau 2 -- Exemple de tableau des caractéristiques des classes.
Dans ce tableau, chaque classe est caractérisée par :
Dans ce tableau, les classes sont triées par valeur d'inertie décroissante. Les premiers thèmes sont généralement les plus importants en taille (colonnes [2] et [3]), ils regroupent les thèmes essentiels du corpus étudié. Pour un nombre de documents égal, plus l'inertie d'une classe est importante, plus les documents constituants sont regroupés de façon pertinente. Par exemple, le thème "Processus acquisition" ([1] = 7,30 ; [2] = 19) regroupe des documents plus homogènes que le thème "Informatique biomédicale" ([1] = 5,95 ; [2] = 19).
Pour apprécier la qualité de la répartition des documents
dans les classes, un premier critère est le nombre de documents ayant
construit la classe [2]. Si quelques classes regroupent l'essentiel des
documents, et si elles correspondent à des mots-clés de
très forte fréquence, elles risquent de masquer une information
plus pertinente. Aussi, il peut être intéressant d'éliminer
ces mots-clés de l'indexation. Dans l'exemple du tableau 2, les deux
premières classes regroupent chacune 33 et 30 documents, ce qui est
à peine supérieur aux classes suivantes; nous pouvons
considérer que les documents sont équitablement
répartis.
Une comparaison entre le nombre de documents ayant construit la classe [2] et
le nombre de documents affectés à cette classe [3] permet
d'estimer la pertinence du seuil des documents :
La colonne [4] permet d'estimer la pertinence du seuil des mots-clés. Nous remarquons qu'un thème homogène (exemple : "Processus acquisition", [4] = 10) est défini par moins de mots-clés qu'un thème plus dispersé (exemple : "Interface utilisateur", [4] = 24).
Les colonnes [5] et [6] permettent d'estimer la dispersion des auteurs et des
sources (titres des revues) autour des thèmes.
Afin de positionner les thèmes obtenus les uns par rapport aux autres, nous représentons les classes obtenues par des points. Une Analyse en Composantes Principales de l'ensemble des points représentant les classes permet de déterminer un plan déformant le moins possible le nuage de points ainsi défini. Tous les points de ce nuage sont ensuite projetés sur ce plan, constituant ainsi la carte des thèmes. Dans le cas présent, nous avons utilisé les coordonnées réelles des thèmes et non le classement par rang, considérant que la carte obtenue (figure 8) restait lisible.

Figure 8 -- Exemple de carte des thèmes obtenue avec NEURODOC.
Sur la carte, la proximité entre deux thèmes indique qu'ils sont définis par des mots-clés issus de domaines connexes. Par exemple, les thèmes : "Hypertexte" et "Interface Utilisateur" sont proches sur la carte, les travaux sur les hypertextes correspondent à un sous-ensemble des problèmes d'interface utilisateur.
La position des thèmes sur la carte est interprétée en
fonction des axes horizontaux et verticaux définissant le plan. Dans un
premier temps, il est important de garder à l'esprit que les
thèmes les mieux représentés sur cette carte se situent
plutôt vers les extrémités des deux axes, c'est-à-dire vers les bords gauche et droit puis haut et bas de la carte. La position
des thèmes situés vers le centre de la carte est moins
significative.
La carte (figure 8) montre que sur l'axe horizontal s'opposent :
Sur l'axe vertical :
Cette carte permet de voir comment s'organisent d'un point de vue thématique les références de ce corpus portant sur "l'intelligence artificielle".
Dans les deux cartes, on trouve 80% de thèmes communs, qui peuvent avoir des intitulés différents (40% de noms identiques), les thèmes applicatifs étant situés vers le haut, les thèmes théoriques étant plutôt situés vers le bas. Le fait que l'opposition thèmes applicatifs/thèmes théoriques soit mise en évidence et rendue de la même manière sur les 2 cartes est fortuit. Dans le cas de NEURODOC, cette position s'explique par le contenu des thèmes. Dans le cas de SDOC, la position des thèmes est expliquée par leur structure. Ainsi, la position des thèmes applicatifs est due à la présence d'une indexation plus spécifique des documents associés. Ceci induit une forte cohésion au niveau des thèmes applicatifs. Les thèmes théoriques sont constitués de mots aux fréquences plus élevées. Leur cohésion est plus lâche, ce qui explique leur position vers le bas sur la carte SDOC.
Deux courts exemples pour illustrer les différences qui existent au
niveau des cartes :
Prenons le thème Apprentissage obtenu avec NEURODOC. Il recouvre les thèmes Apprentissage et Parallélisme obtenus par SDOC. Sur la carte SDOC, ces deux thèmes sont très éloignés mais reliés par une liaison externe, rendant compte d'une liaison structurelle entre un thème spécifique Parallélisme, regroupant 7 documents, et un thème générique Apprentissage qui regroupe 19 documents, dont 4 appartenant au thème Parallélisme.
A l'inverse, prenons le thème "système production" obtenu avec SDOC. Il recouvre les thèmes "automatisation" et "système production" obtenus par NEURODOC. La carte NEURODOC montre que les thèmes "automatisation" et "système production" ont un contenu voisin et constituent un groupe de documents très spécifiques par rapport aux autres thèmes.
Bien que l'hypertexte facilite une démarche d'investigation par association d'idées, nous pensons que l'analyse de l'information peut être pilotée en usant d'indicateurs tels que ceux cités plus haut. Pour les deux méthodes, les étapes de l'analyse sont similaires :
4
- Bilan et évolutions de la station de travail
Notre station de travail permet de caractériser et d'analyser par deux méthodes différentes un ensemble de références bibliographiques. Il nous semble important d'insister encore une fois sur la possibilité de mesurer les accords entre les résultats des deux méthodes d'analyse par des indicateurs globaux (réduction de donnée, taux de recouvrement, nombre de thèmes identiques ou voisins, taille des classes de documents). Il reste cependant que les méthodes offrent des représentations différentes : classes de mots-clés structurées par les relations de cooccurrences dans un cas, classes de mots-clés floues et recouvrantes représentées par des demi-axes dans l'autre. On a vu également que les cartes fournissaient des informations de natures différentes : indicateurs structurels et visualisation des réseaux locaux pour SDOC, oppositions des thèmes selon deux axes principaux pour NEURODOC. Cette richesse au niveau des représentations ainsi que la possibilité de comparer globalement les résultats justifient à notre avis la présence des deux méthodes au sein de la station, chaque méthode apportant un éclairage analytique particulier.
L'interface actuelle pour le pilotage de la chaîne de traitement infométrique est trop rudimentaire dans le cadre d'une utilisation occasionnelle de la station. Nous en avons fait l'expérience au cours de la formation d'un agent à nos outils. L'existence de générateurs d'interface MOTIF nous permet d'envisager avec confiance le développement d'une interface graphique pour le pilotage des modules de traitement et de visualisation. En effet, les fonctionnalités de la station de travail sont maintenant bien stabilisées.
Remerciements
Nota
RéférencesCALLON M., COURTIAL J-P., TURNER W.A., BAUIN S. 1983 - "From Translation to Problematic Networks: An Introduction to Co-Word Analysis" in Social Science Information, vol. 22, pp. 191-235.
CALLON M., LAW J., RIP (eds). 1986 - "Mapping the Dynamics of Science and
Technology", London : The Macmillan Press Ltd.
CALLON M., COURTIAL J-P., PENAN H.1993 - "La scientométrie" - Presses
Universitaires de France, collection "Que sais-je", Paris.
COURTIAL J-P. 1990 - "Introduction à la scientométrie", Anthropos
- Economica, Paris.
DUCLOY J., CHARPENTIER P., FRANÇOIS C., GRIVEL L. 1991 - "Une boîte à
outils pour le traitement de l'information scientifique et technique",
Génie logiciel et systèmes experts, nº 25, pp 80-90, Paris.
DUCLOY J., POLANCO X.1992 -"D'une boîte à outils à la description
du domaine des cognisciences", Journées d'étude ADEST "Prendre la
mesure des sciences et techniques : la scientométrie en action", Paris,
1-11 juin 1992.
GRIVEL L., LAMIREL J.C. 1993 - "An analysis tool for scientometric studies integrated in an hypermedia environment", ICO93, 4th International Conference on Cognitive and Computer Sciences for Organizations, Montréal, (Quebec) Canada, pp.146-154, 4-7 mai 1993.
GRIVEL L., MUTSCHKE P., POLANCO X. "Thematic mapping on bibliographic databases
by cluster analysis: a description of SDOC environment with SOLIS", à
paraître
LEBART L., SALEM A. 1988 - "Analyse statistique des données textuelles",
DUNOD, Paris 1988, 207 pages.
LELU A. 1990 - "Modèles neuronaux pour données textuelles - Vers
l'analyse dynamique des données" - Journées ASU de statistiques,
Tours, France.
LELU A. 1990 - "Modèles neuronaux de projection associative et analyse
des données" - Approches symboliques et numériques pour
l'apprentissage de connaissances à partir des données - sous la
direction d'E. DIDAY et Y. KODRATOFF, pp. 283-305, CEPADUES, Toulouse.
LELU A. 1993 - "Modèles neuronaux pour l'analyse de données
documentaires et textuelles", Thèse de doctorat de l'université
de Paris VI, 4 mars 1993, 238 pages.
LELU A. et FRANCOIS C. 1992 - "Automatic generation of hypertext links in
information retrieval systems", communication au colloque ECHT'92,
Milan, D. Lucarella & al. eds, ACM Press, New York.
PETERS H.P.F., VAN RAAN A.F.J. 1993 - "Co-word based science maps of chemical engineering, Part II : Representations by combined clustering and multidimensional scaling", Research Policy, vol. 22, 1993, p.47-70.
POLANCO X. et FRANCOIS C. 1994 - "Les enjeux de l'information scientifique et
technique à travers une analyse d'infométrie cognitive utilisant
une méthode de classification automatique et de représentation
conceptuelle (NEURODOC)", Actes du colloque ORSTOM/UNESCO "Les sciences hors
occident au XXe siècle, Paris, 19-23 septembre 1994.
POLANCO X. et GRIVEL L. 1994 - "Mapping knowledge: the use of co-word analysis
techniques for mapping a sociology data file of four publishing countries
(France, Germany, United Kingdom and United State of America), Proceedings of
the 4th International conference of Bibliometrics, Informetrics and
Scientometrics - 11-15 Septembre 1993, Berlin, Germany, (article à
paraître en 1994 dans un volume spécial d'Informetrics).
POLANCO X., FRANCOIS C., BESAGNI D., MULLER C., GRIVEL L 1993a - "Le programme
de recherche infométrie", Les systèmes d'information
élaborée, Ile-Rousse, 9-11 juin 1993
POLANCO X., FRANCOIS C., BESAGNI D., MULLER C., GRIVEL L 1993b - "Un exemple de
traitement de l'information par une approche infométrique : le cas de
l'économie de l'information", 3ème conférence
internationale sur la recherche en informations - Nouvelles technologies de
l'information : les défis pour pour la recherche en économie de
l'information, Poigny-la-Forêt, France, 11-13 juillet 1993.
TURNER W. 1994 - "Penser l'entrelacement de l'Humain et du Technique : les
réseaux hybrides d'intelligence "- Solaris nº "Pour une nouvelle
économie du savoir", Presses universitaires de Rennes, pp. 21-50.
Notes
© "Les sciences de l'information : bibliométrie, scientométrie, infométrie". In Solaris, nº 2, Presses Universitaires de Rennes, 1995