



Collecte, pré-traitement et traitement des informations issues du Web dans un environnement coopératif
Taoufiq Dkaki
I.R.I.T. Université Paul Sabatier / IUT Strasbourg Sud
e-mail : dkaki@irit.fr
 |
Résumé Le World Wide Web est devenu une des plus importantes sources d'information accessible de manière électronique. C'est aussi une source d'informations riche pour les chercheurs et les décideurs. Malheureusement, le Web est si énorme et si peu structuré qu'y trouver une information exacte et utile est devenu une tâche titanique très coûteuse en temps. Les moteurs de recherche, les méta-robots et les agents intelligents offrent des réponses à ce problème. Parmi ces outils, certains répondent à des critères d'exhaustivité (i.e. trouver toute l'information disponible pertinente par rapport à une requête donnée). Dans cet article, nous nous proposons d'aborder cette question et d'y apporter une réponse différente. Dans une perspective de prise de décision, nous dépassons la recherche d'information en abordant des aspects d'extraction d'information et d'exploration des données (text mining). Les outils qui existent offrent peu de moyens pour traiter de ce sujet ou proposent des solutions peu réalistes tels l'utilisation du traitement du langage naturel. Nous proposons ici d'utiliser des méthodes qui ont fait leur preuve avec l'information structurée comme les données bibliographiques. Cet article est divisé en trois parties qui correspondent aux points suivants:
Abstract The World Wide Web has become one of the largest sources of information accessible by electronic means. It is also one of the richest sources researchers and decision-makers ever had. Unfortunately, the Web is so huge and so unstructured that finding the right and useful information becomes a titanic and time-consuming task. Search engines, meta-robots and intelligent agents address this issue. Some of these tools partly address the challenge of information exhaustivity (i.e. finding all the available information relevant to a given query). In this paper we deal with this question and propose a different kind of solution. For decision making purposes there is something beyond information retrieval. It is the information extraction and text mining. The existing tools give few and poor means to handle this topic or propose unrealistic or unpractical solutions such as the use of natural language processing. In this paper, we also address this issue. We propose some methods we experimented with structured information such as bibliographic data. This paper is divided in three main sections that correspond to:
|
 Introduction
IntroductionActuellement, nous arrivons aisément à extraire certaines informations factuelles telles que les URLs référencés. Mais, pour une exploitation optimale d'une source d'information telle que le WWW, il faut réaliser un traitement linguistique des documents collectés compte tenu de leur nature essentiellement textuelle. Or ce type de traitement, souvent très coûteux, ne donne pas de résultats probants et est très difficile à mettre en oeuvre dans un contexte ouvert.
Nous proposons une autre alternative qui consiste à faire collaborer deux sources d'informations le Web et les banques de données traditionnelles. Cette méthode consiste à exploiter les connaissances issues des banques de données pour les injecter dans les informations issues du Web. Cette collaboration permettra de mieux approcher le sens et le contenu des documents issus du Web sans pour autant avoir recours aux techniques du traitement du langage naturel.
Dans cet article, nous aborderons trois grands sujets:
Le premier sujet concernera la collecte et le filtrage de l'information sur le web. Le deuxième sujet traitera du pré-traitement de l'information qui inclut la prise en compte des connaissances extraites des bases de données traditionnelles. Le dernier sujet abordera le traitement des informations pré-traitées. Lors du traitement de ce dernier sujet il sera question du logiciel Tétralogie et la collaboration entre les méthodes d'analyse qu'il propose.
Collecte
et filtrage d'informations issues du Web
Il est inutile de préciser que le Web est devenu une source incontournable et incontournée d'informations à haut potentiel stratégique. Rappelons toutefois les grandes méthodes d'utilisation des informations du Web qui restent largement insuffisantes pour une exploitation optimale et sont essentiellement liées à des besoins d'accès à l'information.
Ces méthodes se déclinent en trois variantes:
Dans tous les cas, l'information collectée est réduite à des URLs ou à des documents HTML. La quantité d'information retournée empêche souvent tout traitement manuel efficace. En effet il n'est pas rare d'avoir plusieurs milliers d'URLs. De plus, il arrive qu'on se retrouve avec beaucoup d'information non pertinente.
Les moteurs de recherche tels que AltaVista, Hotbot, Lycos et bien d'autres [Beaucoup] sont utilisés pour localiser des URLs potentiellement pertinentes pour une requête et donc pour un besoin informationnel donné. Ces systèmes scrutent périodiquement le Web et mémorisent l'association entre les adresses URLs et des termes d'indexation correspondant à leur contenu. En général un moteur de recherche n'a qu'une connaissance partielle des documents du Web. Pour augmenter ses chances de retrouver la totalité ou, tout au moins, la plus grande quantité de documents en rapport avec un sujet donné, il faut faire collaborer différents moteurs de recherche. C'est le propos des méta-moteurs de recherche tels que MetaCrawler, Copernic, Fusion et bien d'autres [Veille]. Un méta-robot envoie la requête à plusieurs robots en parallèle, récupère et combine les adresses retournées par chacun d'eux. Ainsi, le nombre potentiel de pages Web visitées est plus important. De plus, les méta-robots effacent généralement les adresses dupliquées et dans certains cas s'assurent de leur validité.
Cependant, quel que soit le système utilisé (robot ou méta-robot), les URLs retrouvées peuvent s'avérer non pertinentes ou non valides, soit parce que la page n'est plus disponible, soit parce qu'elle est protégée soit pour d'autres raisons (consulter le RFC correspondant au protocole HTTP). Rappelons que le fait de détecter qu'un document est protégé peut être en soi une information stratégique.
De plus, l'objectif final d'une recherche d'informations est généralement de transformer l'information pertinente en connaissances. L'utilisateur doit créer sa propre représentation des informations retrouvées, en fonction de ses connaissances sur le domaine. Pratiquement, aucune aide n'est fournie aux utilisateurs dans ce processus.
Pour résoudre ces problèmes, nous proposons d'ajouter une nouvelle couche dont l'objectif est double :
Il s'agit donc de deux approches différentes qui consistent soit à utiliser les outils existants : méta-moteurs, agents intelligents, aspirateurs ... soit à créer ses propres outils avec une double fonction de collecte d'URLs et d'aspiration des documents associés.
Bien sûr, une autre solution consisterait à créer sa propre araignée, son propre moteur de recherche. Mais c'est une solution non envisageable à moins de posséder les moyens d'AltaVista ou d'un de ses concurrents.
Ces deux solutions présentent des avantages et des inconvénients. L'utilisation des outils existants est plus simple. Souvent les outils proposés sont très ergonomiques et s'interfacent avec un très grand nombre de moteurs, jusqu'à 250 moteurs pour certains. Par contre, ces outils sont, pour la plupart, pensés pour la navigation. D'autre part, il faut deux outils : un pour collecter les URLs, un pour aspirer les documents associés.
Le point le plus important est que généralement les documents collectés sont transformés dans un format propriétaire, ce qui les rend difficiles à traiter.
Bien qu'il s'agisse de méta-moteurs, la plupart d'entre eux ne retournent qu'un nombre limité d'URLs, parfois en double, traduisant ainsi les limitations propres aux moteurs de recherche. Par exemple, AltaVista ne retournera jamais plus de 1000 URLs bien qu'il en annonce parfois plusieurs dizaines de milliers.
La solution de créer ses propres agents présente l'avantage de n'avoir aucune limitation, mises à part celles de ses capacités, de son imagination et celles induites par les protocoles (HTTP) et les langages(HTML) utilisés.
En ce qui concerne les inconvénients, cette deuxième solution implique la connaissance des langages d'interrogation utilisés par chaque moteur de recherche ainsi que HTML, exige de constamment se tenir au courant des évolutions de ces langages et nécessite de les répercuter au niveau de l'outil de collecte.
 Proposition
d'une méthode de Collecte de l'information
Proposition
d'une méthode de Collecte de l'information
L'outil que nous avons proposé s'appelle WHaT [Dkaki 1998] pour Web Harvesting Tool. WHat a pour tâche de récupérer l'information brute (les pages Web). Il fonctionne selon le schéma suivant :
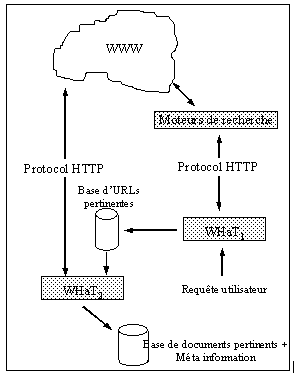 WHaT crée une base de données des URLs qui ont
été retrouvées par un ou plusieurs moteurs de recherche;
il vérifie la validité des URLs et efface les URLs
dupliquées. Il a aussi en charge de collecter les pages Web.
Actuellement, l'interface avec le moteur AltaVista et le
méta-moteur Fusion2 fonctionne ; d'autres interfaces peuvent
facilement être intégrées.
WHaT crée une base de données des URLs qui ont
été retrouvées par un ou plusieurs moteurs de recherche;
il vérifie la validité des URLs et efface les URLs
dupliquées. Il a aussi en charge de collecter les pages Web.
Actuellement, l'interface avec le moteur AltaVista et le
méta-moteur Fusion2 fonctionne ; d'autres interfaces peuvent
facilement être intégrées.
Les algorithmes de WHaT sont les suivants:

Algorithme 1 : Collecte des URLs.

Algorithme 2 : Collecte des documents.
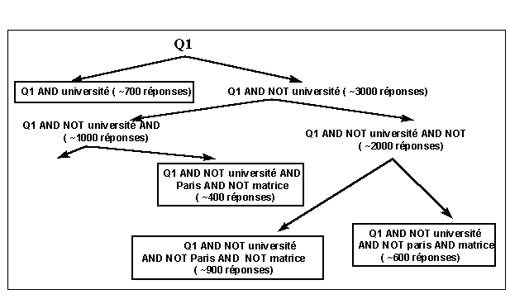
Nous explicitons la méthode de discrétisation par l'exemple suivant:
Supposons que l'on souhaite collecter tous les documents qui parlent de Mathématique, d'Algèbre et de France. AltaVista trouverait 4 000 URLs. Au mieux, il restituerait 1 000 documents.
Nous proposons de partitionner l'ensemble résultat selon le processus hiérarchique et itératif qui consiste à remplacer une requête Q1 aboutissant à plus de 1000 URLs, par deux requêtes complémentaires Q1 AND MOT et Q1 AND NOT MOT. Dans ce processus, une requête sera considérée comme terminale (bonne) si et seulement si elle correspond à moins de 1000 URLs. La figure suivante, sous la forme d'un arbre dont la racine représente l'équation d'origine et les feuilles représentent les requêtes terminales, illustre ce processus.
Filtrage
de l'information brute
Ce filtrage est basé sur des techniques classiquement utilisées en recherche d'informations et qui ont fait leurs preuves dans le domaine de la recherche d'information... Il s'agit de calculer un degré de ressemblance entre la requête initiale de l'utilisateur et le contenu des documents. Seuls les documents ayant un degré de similitude supérieur à un certain seuil seront considérés comme pertinents. Nous avons choisi d'utiliser une fonction cosinus qui prend en compte l'occurrence des termes de la requête dans le document traité ainsi que la taille du document.
La ressemblance de la requête Q et du document Di est calculée par :
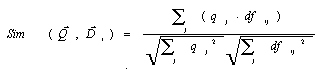
Extraction
d'informations
Afin d'extraire de la connaissance à partir de l'information brute collectée, nous proposons d'utiliser la structure logique des documents HTML.
ReformatageUne fois le problème de collecte et de filtrage résolu nous nous attaquons à la phase de pré-traitement. Cette phase a pour objectif principal de faciliter l'extraction de l'information tout en réutilisant les outils existants : pour ce qui nous concerne, l'outil Tétralogie [TETRA].
Pour ce faire, il faudrait se ramener à des formats exploitables par Tétralogie, et d'ailleurs par la plupart des logiciels français de veille, qui sont pour la plupart des formats bibliographiques.
La solution consiste à réécrire les documents HTML. Un traitement lexical prenant en compte le balisage HTML est suffisant pour réaliser cette tâche. En réalité nous prenons aussi en compte des méta-données du type dates de création ou de modification des documents, leurs tailles, leurs langues...
L'exemple suivant montre la réécriture d'un document.

Extraction des groupes de mots : coopération web/bases traditionnellesDans le contexte de la recherche et du traitement de l'information, nous sommes souvent amenés à travailler sur du texte intégral, ce qui est le cas quand il s'agit de documents issus du Web. A défaut d'un système de traitement du langage naturel qui soit opérationnel et performant, nous nous restreignons à l'utilisation de traitements statistiques.
La méthode des multitermes permet d'améliorer ces traitements. Elle permet de passer de la représentation du texte intégral sous la forme d'une succession de mots isolés, à une représentation sous la forme d'une suite de "concepts". Un concept est lui-même décrit par une suite de mots (multitermes). L'utilisation de groupes de termes plutôt que des termes simples a fait l'objet de nombreuses études en recherche d'informations [MITR97]. Les statistiques sont alors effectuées sur les concepts et non sur les mots isolés, ce qui a pour conséquence une meilleure approche du sens du texte.
Prenons par exemple la phrase suivante : “J'ai assisté à un cours d'analyse de données où j'ai appris la méthode d'analyse en composantes principales”.
Là où les méthodes traditionnelles dissocient le mot "analyse" du mot "données" et le mot "composantes" du mot "principales", la méthode des multitermes consiste à associer d'une part "analyse" et "données" et d'autre part "analyse", "composantes" et "principales". Les bases du traitement statistique deviennent alors les locutions : "analyse de données", "analyse en composantes principales". Le gain, du point de vue sémantique, est indéniable.
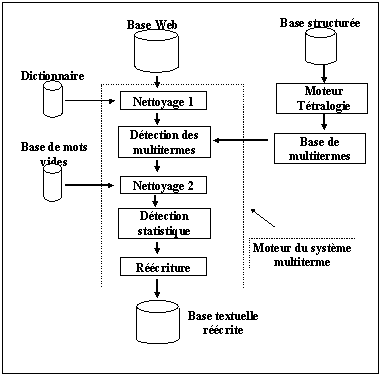
La détection des multitermes peut être réalisée en cinq étapes :
L'extraction des groupes de mots peut être dirigée, c'est-à-dire que l'on peut choisir les composants structurels à partir desquels l'extraction doit être réalisée (par exemple, à partir des titres).
Un élément important est que les groupes de mots sont détectés à partir des seules informations collectées ; ainsi, ils dépendent du contexte étudié et sont plus représentatifs.
De plus, la connaissance a priori d'un ensemble de groupes de mots peut être prise en compte (étape 2). Cet ensemble peut être le fruit du travail d'un expert ou peut être extrait de manière automatique à partir d'une base de données traditionnelle par exemple du champ mots-clés. Dans ce cas les connaissances extraites des bases traditionnelles collaborent à une exploitation optimale des informations issues du Web.
Le schéma de cette utilisation est le suivant:
Extraction des référencesLes hyperliens dans les documents HTML sont marqués par des balises spécifiques et peuvent donc être extraits facilement (nous utilisons l'analyseur W3C pour détecter ces liens).
Différents types de références peuvent en fait être détectés :
Filtrage
des informations extraites
Résumé
de l'information
Ces fonctions de cooccurrences sont décrites par le schéma suivant:
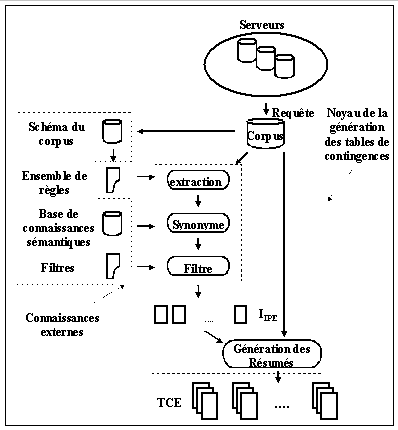
Découverte
d'informations avec Tétralogie
Pour Tétralogie, il s'agit :
Ces tables sont utilisées comme entrées des méthodes d'analyses : AFC, ACP [Benzecri 1973], CPP, CAH.
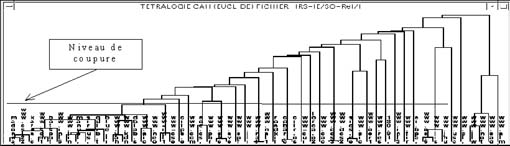
Les classifications supposent que l'on ait un ensemble d'éléments à classer et que l'on ait un critère qui permette d'évaluer la proximité ou la ressemblance entre deux groupes et a fortiori deux éléments de cet ensemble. Dans le cas des tables de contingences à deux dimensions, l'ensemble d'éléments à classer est celui des instances de la première information potentiellement exploitable (cf paragraphe précédent) et le critère est une distance entre éléments dans le référentiel induit par les instances de la deuxième information potentiellement exploitable. En utilisant par exemple une classification ascendante hiérarchique avec la distance euclidienne entre éléments et la distance moyenne, inférieure ou supérieure entre classes, nous obtenons une partition des données et un indice de qualité de cette partition, ce qui permet d'ailleurs d'automatiser le processus de classification. L'exemple suivant montre une classification issue du croisement URLs / thématique où les URLs sont classées par rapport à leurs contenus.
Les classifications basées sur les théories des graphes [DKAK95] permettront, dans le cas des informations issues du Web, de déterminer les réseaux de cocitations entre les documents HTML.
Pour la recherche des associations, nous partons toujours d'un tableau de contingence à deux dimensions. Les corrélations sont à rechercher entre instances de la première information potentiellement exploitable et instances de la deuxième information potentiellement exploitable. L'utilisation d'analyses factorielles telles que l'AFC permet de représenter les deux types d'instances dans un même référentiel. Dans l'espace factoriel ainsi construit, les proximités entre instances des deux types traduisent alors l'existence de corrélations.
Pour la découverte de séquences, nous utilisons des tables de contingences à trois dimensions où la troisième IPE représente le temps. Ce sont donc des données cubiques qui peuvent être représentées sous forme d'une série chronologique de tables de contingences à deux dimensions. Nous utilisons alors les techniques d'analyse factorielle pour dégager les corrélations à chacun des instants. Les méthodes d'analyses factorielles multiples permettent la comparaison de ces corrélations. De plus, des méthodes comme l'analyse procustéenne permettent de transformer la série temporelle en enlevant et en gommant l'évolution globale des données pour ne laisser que l'évolution relative.

Exemple
basé sur une requête sur AltaVista
ConclusionLe traitement du texte libre, que nous avons proposé et qui tient compte de connaissances extraites de bases de données traditionnelles, constitue une alternative honorable au traitement linguistique des pages Web.
Une application des techniques que nous avons détaillées peut être le filtrage puis le traitement des informations qui sont télédéchargées depuis les différentes sources d'information actuellement disponibles sur l'internet (les News , les documents HTML etc...). En effet, quelle que soit la source de l'information et son mode d'interrogation, le résultat comporte presque toujours du bruit. Il est donc nécessaire de le filtrer afin de ne garder que les documents les plus pertinents.
Ces méthodes ont déjà été utilisées dans des cas réels, notamment pour l'exploitation des informations issues des groupes de News.
Remerciements
Bibliographie
© "Solaris", nº 5, janvier 1999.