



De l'émergence des concepts : réflexions à partir du traitement "neuronal" des bases de données documentaires
Alain LELU
 |
A partir du traitement "neuronal" des gros corpus documentaires, on
s'interroge ici sur les conditions d'émergence des concepts, sur les
possibilités de modélisation de cette émergence, de telle
sorte que le processus de conceptualisation puisse, ne serait que de
façon schématique être implanté dans un programme
d'ordinateur sans en trahir les traits fondamentaux. Située au croisement de l'analyse des données et des réseaux neuronaux formels, cette approche tend à cerner un certain nombre de problèmes et difficultés théoriques et pratiques mis à jour par le courant du néo-connexionnisme. Avec la généralisation de l'informatique et l'accumulation de textes saisis de façon électronique, en particulier celle qui se poursuit au fil des ans dans les systèmes documentaires, le problème de manque d'information qui était généralement le lot du genre humain fait place au problème inverse : celui de sa pléthore, qui aboutit aussi efficacement que la pénurie à la même opacité. D'où l'idée qu'appliquer des procédures de traitement automatiques à ces flots d'information (eux-mêmes souvent issus de sources automatiques !) est une des voies possibles pour traiter le problème ; l'autre voie , réduire le flot des informations, semble peu réaliste, compte tenu de la tournure déjà prise par les événements.
Qui dit réduire un flot d'informations dit aussi abstraire, produire des concepts, c'est-à-dire des synthèses d'un grand nombre d'informations élémentaires. Le processus humain d'abstraction est complexe. Il est d'autant plus opaque qu'il est difficile d'en être à la fois les observateurs et les observés. Il fait intervenir le langage, le raisonnement, mais aussi des phénomènes largement inconscients comme notre perception du monde et de notre propre identité.
Quand la démarche scientifique s'empare d'un phénomène, elle cherche à le réduire à un "squelette" assez pauvre pour qu'il soit appréhendable par notre intellect, mais sans que cela en détruise les caractéristiques essentielles. Le phénomène est alors "stylisé" -- les mathématiciens parlent souvent d'élégance : un maximum d'effets pour un minimum de moyens. Peut-on simplifier le processus de conceptualisation, l'épurer au plus près pour qu'il puisse être implanté dans un programme d'ordinateur, sans trahir ses traits fondamentaux ?
Je propose ici une approche possible, située au confluent des disciplines scientifiques dénommées "analyse des données" et "modèles neuronaux". Cette approche n'est pas théorique ; elle a conduit à des développements d'algorithmes opérationnels sur des données de taille réelle, comme le montrera l'exemple fourni. Elle s'appuie aussi sur de nombreux développements passés qui seront cités dans l'annexe bibliographique ("Pour en savoir plus").
|
 Qu'est-ce
qu'un concept ? Comment le représenter ?
Qu'est-ce
qu'un concept ? Comment le représenter ?
En nous situant à un niveau délibérément minimal de description et maximal de généralité, nous introduisons la notion de "micro-monde". Un micro-monde pourrait être ce que perçoit une "machine à recueillir des données" disposant d'un certain nombre de "capteurs". Chaque état du micro-monde est défini par l'ensemble des valeurs affichées par ses capteurs à un moment donné.
La définition du micro-monde se réduit à la collecte de tous les états qu'il a pu prendre au cours d'une campagne d'observation donnée. Considérez par exemple l'ordinateur central d'une usine chimique surveillant les processus qui s'y déroulent, mais aussi un serveur sur réseau Télétel recueillant les réponses des personnes qui s'y connectent à un ensemble de questions, entre autres possibilités - des réponses par oui ou non peuvent se coder 1 ou 0. Chaque questionnaire nouvellement rempli constitue un nouvel "état" de ce micro-monde plutôt fruste et peu attrayant. A défaut, reconnaissons-lui le mérite d'être général, et que souscrire à cette vue des choses ne nous engage guère pour le moment...
Nous verrons à la fin de ce texte qu'il est possible de concevoir des univers moins statiques, plus subjectifs, plus vivants que diable ! ... mais hélas plus difficiles à modéliser et à maîtriser par les jeux des formalismes mathématiques et de la simulation informatique réunis auxquels nous nous livrons.
Pour l'instant nous n'en sommes pas là, et je vous enjoins de vous contenter de ces univers peu appétissants à première vue, univers qu'un esprit chagrin pourrait comparer à de vastes et rectangulaires cimetières d'informations. C'est ceux-ci que je défendrai désormais bec et ongles, et j'espère bien vous montrer qu'ils ont leurs charmes, et qu'on peut en tirer des choses étonnantes pour peu qu'on s'y prenne de la bonne façon.
Reprenons : chaque état, chaque observation, est décrit par les valeurs d'un ensemble fini de caractères observés (les grandeurs physiques mesurées, les questions posées, ...). Pour simplifier encore, bien que ce ne soit pas indispensable, nous admettrons que ces variables, ces "observables", sont de nature qualitative, ce qui permet de représenter mathématiquement chaque état par un ensemble de valeurs "1" (pour les événements observés), et de "0" (pour ceux qui ne l'ont pas été). Nous avons affaire ici à un cas (binaire) de vecteur décrivant chaque observation - un vecteur est un ensemble informe de nombres sans ordre défini a priori, un "sac" où ces nombres sont déversés en vrac. Attention, chaque vecteur, chaque sac contient toujours le même nombre d'éléments - c'est la contrainte minimale pour qu'il soit possible de définir des opérations sur ces êtres un peu bizarres, mais bien commodes, que sont les vecteurs.
On a l'habitude de représenter un vecteur par une ligne (ou une colonne, pure question de goût !) d'un tableau de nombres (fig. 1) : représentation commode, mais trompeuse car il ne faut jamais oublier que l'ordre de présentation des valeurs sur la feuille de papier n'est pas censé exister, et provient d'un choix arbitraire de pure présentation.

Figure 1 -- Représentation d'une observation.
Ici, les caractères Nº 2, 5, 6, 10, 16, 17 sont
présents, parmi les 18 caractères possibles.
Avec ces conventions, notre micro/monde sera décrit par le tableau de "0" et "1" rassemblant la totalité des états observés (fig. 2), et comprenant autant de lignes que de ces états.

Figure 2 -- Représentation d'un ensemble d'observations.
(par exemple : un ensemble de documents
définis chacun par quelques mots-clés parmi
un vocabulaire de 18 termes).
L'exemple-type d'un tel micro-monde est le questionnaire d'enquête passé auprès d'une population de J individus, auxquels on pose I questions à réponses par oui ou non. Dans notre approche, on ne prend en compte ni l'ordre dans lequel les questions sont posées, ni l'ordre de recueil des différents questionnaires, bien que l'on se trouve en face d'un tableau de nombres dont les lignes et les colonnes seront nécessairement ordonnées sur le papier. On peut permuter tant qu'on veut les lignes ou les colonnes du tableau : l'information que nous prendrons en considération sera toujours la même.
Un autre exemple est fourni par les bases de données documentaires : chaque document est décrit, "indexé" en terme du métier, par un nombre variable de descripteurs, dits "mots-clés". Les documents se trouvent généralement en quantité importante -- typiquement quelques milliers à quelques millions -- mais pas infinie ; Monsieur de La Palisse en aurait-il déduit que le nombre des mots-clés est lui aussi fini (typiquement quelques centaines d'unités à quelques dizaines de milliers) ? Espérons-le, et constatons qu'il est équivalent de traduire un tel ensemble d'informations de façon condensée par un ensemble de listes de mots (ou mieux : de numéros de mots) décrivant chaque document, ou de façon moins condensée mais homogène avec notre approche par un immense tableau de J lignes et I colonnes où prédominent les "0" par rapport aux "1" (fig. 3). Bien sûr en pratique, seule la première représentation (listes de descripteurs) est engrangée dans les programmes informatiques, mais la deuxième (tableau de nombres) présente pour nous un intérêt conceptuel essentiel, et nous aidera à raisonner au sujet des traitements d'informations possibles.

Figure 3 -- Autre présentation d'un
tableau d'observations.
Comment synthétiser, "abstraire" de tels micro-mondes ? Nous ne nous attarderons pas sur la méthode "marteau-pilon" usuelle qui consiste à écraser le tableau dans le sens de la hauteur, pour n'en laisser subsister qu'un "profil" général : le comptage des réponses pour l'ensemble des questions (pour reprendre l'exemple du questionnaire, comptage que les professionnels concernés appellent à juste titre "tri à plat"), ne donne qu'une idée globale de l'orientation générale des réponses - idée indispensable de toute façon, quels que soient les perfectionnements ultérieurs de l'analyse ; on peut raffiner en répétant l'opération pour plusieurs sous-populations ("ouvriers", "cadres supérieurs"...) que l'on se fixe a priori -- ce sont les fameux tris croisés qui fleurissent en périodes électorales --, mais notre idéal est plus subtil : nous voudrions que les données "parlent" d'elles-mêmes, sans que l'on ait à leur soutirer au forceps l'organisation dont elles font fatalement preuve, pour peu qu'elles n'aient pas été engendrées au hasard et qu'elles soient le reflet de réalités tangibles.

Figure 4 -- Tableau d'observations
après permutation des
lignes et des colonnes
(méthode graphique de
J. Bertin).
Puisque l'ordre des lignes et des colonnes est indifférent, profitons-en : une première approche consiste à ré-ordonner à la main les lignes et les colonnes (c'est la méthode graphique due à Jacques Bertin [J. Bertin 1977]) jusqu'à obtenir un tableau où la zone autour de la diagonale comporte une proportion plus élevée qu'ailleurs de "1" par rapport aux "0" (fig. 4).
On peut mettre ainsi en évidence une structure d'opposition entre deux groupes de lignes (ou deux groupes de colonnes, c'est la même chose) pour lesquels les "1" des uns sont quasi-systématiquement les "0" des autres. Entre ces deux pôles s'étend un continuum de lignes (resp. colonnes) intermédiaires. Cette approche, à quelques nuances près pour les puristes, est équivalente à celle consistant à appliquer aux données -- automatiquement cette fois... -- une méthode dite d'analyse factorielle, dans laquelle le nombre de "facteurs" extraits est égal à un. Un facteur est un indice, un nombre attaché à chaque ligne (resp. chaque colonne) permettant de classer les lignes (resp. colonnes) entre elles. Insistons sur le fait que personne n'attache de telles valeurs d'indices aux lignes, mais qu'elles s'attachent toutes seules, d'une façon totalement automatique dont vous aurez une idée, j'espère, si vous persévérez dans la lecture de ce texte.
Pour obtenir une représentation graphique plus parlante, il suffira de reporter les noms des lignes (ou des colonnes) le long d'un axe ; c'est alors que pourra se produire un phénomène d'apparition de sens : tandis que le traitement du tableau, manuel ou automatique, n'est qu'un processus stupide et mécanique de manipulation de nombres, l'ordre des libellés de lignes et de colonnes ne vous paraîtra pas arbitraire, et évoquera en vous des associations que vous connaissiez déjà, qui vous paraîtront vraisemblables, voire franchement triviales (cf. fig. 5) : "Bon sang mais c'est bien sûr ! les lecteurs de "Nous-Deux" s'opposent à ceux de "L'Express", les manoeuvres aux professions libérales ! Et dire que c'est l'ordinateur qui trouve ça tout seul !".
Voici donc un premier exemple d'extraction de ce qu'il est difficile d'appeler autrement qu'un concept, qui résume comment deux faisceaux de descripteurs (ou d'objets décrits) s'excluent mutuellement, mais aussi organisent un espace où se situent des descripteurs (et objets décrits) intermédiaires. Bien que les positions des uns et des autres soient données par des nombres, il n'y a rien de bien quantitatif là-dedans : il s'agit surtout de marquer l'existence d'oppositions bien tranchées, d'une part ; mais aussi de degrés d'appartenance à un pôle ou à un autre, toutes caractéristiques que nous verrons définir a minima la notion de concept. Au gré des données analysées, on verra les électeurs de droite s'opposer à ceux de gauche, les femmes s'opposer aux hommes, les extravertis aux introvertis, etc. -- concepts triviaux, évidents, mais - ô miracle -- ils apparaissent automatiquement. Du reste ce miracle s'est bien banalisé depuis une vingtaine d'années, et les cartes factorielles issues des instituts de sondage n'étonnent plus personne ; on y voit les "décalés" s'opposer aux "recentrés" et autres "planeurs polymorphes" [B. Cathelat 1990]...

Figure 5 -- Représentation factorielle
des lignes d'un tableau d'observations
(ici les titres de la presse française,
décrits par les caractéristiques
socio-professionnelles de leurs lecteurs).
Admirons l'opération : au départ on avait une matière brute peu engageante sous sa forme de grand tableau de nombres, qu'on aurait pu à la rigueur apprendre par coeur (mais personne n'a guère envie de le faire) ; à l'arrivée, on a deux listes ordonnées de libellés compréhensibles. Les libellés, qui se "ressemblent", s'assemblent dans les mêmes zones de la liste ; ceux qui "s'opposent", se repoussent aux deux extrémités ! Dès lors tout s'éclaire, et l'on se sent capable de faire un résumé communicable du contenu du tableau, même si l'on ne retient pas bien la position exacte des libellés centraux, dont tout le monde se moque, puisque le but de l'exercice est de savoir en gros ce qui ressort le plus des données considérées, ce qui est le plus marquant, dans le tableau considéré, et d'ignorer le "marais" restant ! A noter que le sens d'ensemble, pour lequel le "marais" est prépondérant, nous a été révélé par le tri à plat vu plus haut.
Arrivés à ce point, il faut préciser que les concepts extraits sont d'une espèce bien particulière : ils vont par paire, par couple d'oppositions. Par exemple, l'analyse d'une enquête de lecture de périodiques oppose, comme on pouvait s'en douter, la presse des lecteurs riches et instruits à celle des lecteurs pauvres et tôt exclus du système scolaire. Mais tous les concepts ne vont pas par paire : beaucoup n'ont pas de terme opposé, ils ne marquent que des conglomérats de faits saillants par rapport à la morne plaine de tous les autres (à quoi s'oppose une table ?). L'approche très globale de l'analyse factorielle, dans laquelle chaque élément (ligne ou colonne) trouve sa place par rapport à la totalité des autres, est moins adaptée pour les tableaux très "vides", sous lesquels se cachent des données que des psychologues anglo-saxons ont dénommé "pick-any". Ces données se présentent sous la forme de courtes listes de descripteurs choisis parmi une longue liste, laquelle peut atteindre des milliers d'éléments ; c'est typiquement le cas des descriptions de documents par des mots-clés, où chaque document est caractérisé par environ cinq à quinze mots-clés choisis dans un vocabulaire pouvant atteindre des dizaines de milliers de mots. Dans ce cas la présence d'un descripteur ne signifie jamais systématiquement l'absence d'un autre précis (ou d'un groupe précis d'autres) plutôt que de n'importe lequel autre.
Dans ce cas de figure qui nous intéresse au premier chef, il est par contre possible de détecter des groupes de lignes et de colonnes tels que la proportion des "1" par rapport aux "0" soit forte à l'intérieur de ces groupes, et très faible au-dehors (fig. 6). On peut décrire alors le micro-monde considéré comme un ensemble a priori désordonné de logiques beaucoup plus locales. Chaque classe trouvée - elle comporte à la fois des lignes et des colonnes - peut être interprétée comme un "concept" rudimentaire extrait des données : l'ensemble de ses lignes décrit tous les exemples du concept trouvés dans le micro-monde, ce que les classiques appellent depuis Aristote l'extension du concept ; l'ensemble des colonnes décrit les traits qui lui sont propres et définit le concept en compréhension. Extension et compréhension sont indissociables, ce sont les deux faces d'une même médaille - la médaille, c'est une partie de notre tableau de données, l'ensemble des illustrations du concept, qui peuvent être énumérées en ligne (l'extension), ou décrites par colonnes (la compréhension).
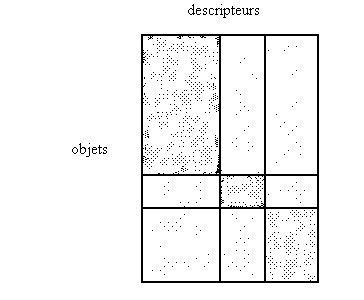
Figure 6 -- Tableau de données réordonné
après
sériation par blocs.
 Méthodes de classification automatique
Méthodes de classification automatiqueParlons un peu technique : en analyse des données, ce sont les méthodes dites de "sériation par blocs" qui se sont attachées à résoudre ce type de problème, c'est à dire à constituer simultanément un ensemble de classes sur les lignes et sur les colonnes. Les méthodes beaucoup plus connues dites de classification automatique se contentent de constituer des classes de lignes seules, ou de colonnes seules. Dans ce dernier cas (des colonnes seules), on constitue un tableau intermédiaire, le tableau des cooccurrences, qui condense l'information du tableau initial, au prix de la perte de l'information sur les lignes individuelles : chaque case de numéro (i1, i2) de ce tableau comporte le nombre de fois où les lignes du tableau originel ont été décrites simultanément par les descripteurs i1 et i2 (fig. 7). La méthode Leximappe décrite en détail par ailleurs [Courtial 1990] suit cette dernière démarche de classification des colonnes, appliquée aux tableaux de cooccurrence de mots-clés tirés de bases de données documentaires ; elle établit une classification de ces mots ; le caractère tout ou rien de toute classification est ici adouci par des indicateurs de liens entre mots de chaque classe et mots extérieurs à cette classe.

Figure 7 -- Construction d'un tableau de cooccurrences
à partir d'un tableau de données qualitatives.
Pour être plus concis, étant donné un tableau X de données (fig. 8), il est possible d'en tirer deux tableaux résumés croisant les éléments (lignes ou colonnes, observations ou descripteurs, individus ou variables, documents ou mots-clés...) avec les classes obtenues par une technique de classification :

Figure 8 -- Tableaux résumés d'un tableau X
(cas de la sériation par blocs =
classification en tout ou rien sur
les lignes et les colonnes).
Dans les deux cas Yc et Yl sont des tableaux de valeurs 0 et 1, et n'ont qu'un seul "1" par élément décrit. Tout cela pour en venir aux points qui suivent :
Digression terminologique et neuronale sur le mot classification
Attention aux faux-amis : beaucoup d'auteurs américains se sont
mis à employer le terme "classification" dans un sens différent
du mot français, sens qui correspondrait plutôt à notre
terme "classement". Pour eux, il s'agit d'automatiser l'opération
d'identification d'une "forme" donnée -- par exemple une
image -- à des catégories humainement établies depuis
longtemps ; ainsi peut-il s'agir de faire dire à un ordinateur
"ceci est un A" à partir de l'image d'un caractère d'imprimerie ?
Les choses se passent en deux phases : on présente à la
machine un ensemble d'exemples, avec pour chaque exemple la catégorie
correcte à laquelle il appartient -- c'est la phase dite
d'apprentissage. Puis on présente au système des formes
nouvelles, dont il indique alors la catégorie (phase de
généralisation) ; on compte alors le taux d'erreur, qui peut
descendre à moins de 1% en reconnaissance de caractères (1%
représente quand même 20 fautes par page en moyenne...).
Par
rapport à notre approche, on peut dire qu'à partir d'un
même micro-monde d'exemples, nous cherchons à réaliser un
auto-apprentissage des données qui en mette à jour les
catégories pertinentes, alors qu'il s'agit dans l'approche
américaine de "forcer" l'apprentissage de catégories
étrangères au système sous l'action d'un "superviseur",
d'un "professeur" supposé omniscient... Une telle approche comporte des
risques : si rien dans les exemples donnés en pâture au
système n'est corrélé avec les catégories humaines
préétablies, la moulinette informatique n'en fonctionnera pas
moins et reconnaîtra correctement les exemples, mais son pouvoir de
généralisation à de nouvelles formes sera nul ; pour
que l'approche fonctionne, il faut qu'il existe "quelque chose" dans les
exemples donnés qui soit en relation avec les catégories que
reconnaîtrait un homme, quitte à ce que ce "quelque chose" soit
très subtil. Ce qui devrait être détecté de toute
façon par une bonne analyse non supervisée (je ne dis pas
que c'est le cas actuellement !). Du reste, c'est l'utilisation de
l'information contextuelle qui explique souvent les performances
humaines ; essayez un peu de reconnaître des caractères
manuscrits découpés et présentés dans le
désordre !
L'approche reconnaissance avec superviseur a beaucoup de succès à cause de son aspect "boîte noire", et on peut dire que la majorité des recherches sur les modèles neuronaux [1] partent de cette problématique ; personnellement, je n'aime pas trop cette approche, même si je reconnais qu'elle a le mérite de placer la barre très haut pour les méthodes non supervisées. L'analyse des données, discipline plus ancienne, moins soumise aux effets de mode -- ou plutôt : qui a eu son heure de mode 20 ans avant les réseaux neuronaux... -- utilise le terme "analyse discriminante" pour désigner ce que les auteurs américains appellent "classification". Les réseaux neuronaux correspondent tout bonnement à un renouveau de l'analyse discriminante dite non linéaire, et, dans une moindre mesure, de la classification automatique. Mais, me direz-vous, comment traduire classification automatique en anglais ? Par "cluster analysis", mon cher Watson !
Bien que l'acception du terme classification ait été la même en Angleterre dans les années 1960 que chez nous, et persiste encore à l'état de trace historique dans le titre du Journal of Classification américain, le sens américain tend à se répandre, et contamine inévitablement les milieux français concernés. Si on vous vend un logiciel de classification à base de modèles neuronaux, sachez qu'il y a toutes chances pour que ce logiciel effectue de l'analyse discriminante et de la reconnaissance des formes avec superviseur, mais pas de la classification automatique !
Psychologie et concepts humainsL'étude expérimentale de la nature des concepts humains par les psychologues n'est pas nouvelle. Un courant important de la psychologie cognitive [Rosh et al. 1976, Dubois 1991] a mis en évidence :
Il est bien connu par ailleurs que certains exemples sont ambigus, et peuvent illustrer plusieurs concepts, éventuellement avec une "force" différente. Ceci est particulièrement clair avec notre exemple des mots-clés d'une base de données documentaire : un même mot peut avoir deux significations différentes selon l'environnement de mots dans lequel il se trouve, c'est-à-dire selon son contexte. Et chaque concept, faisceau de traits cooccurrents en moyenne, constitue bel et bien un tel contexte.
A noter que par définition les traits sont ambigus, et qu'un même trait peut intervenir dans plusieurs concepts. Ceci est d'ailleurs trivial : les traits n'intervenant que dans un seul concept se confondent avec ce concept ! C'est en grande partie la combinatoire des traits qui peut définir un concept en compréhension. Mais c'est une combinatoire pondérée, car chaque trait n'a pas partout le même poids. D'où l'idée d'une variante de nos tableaux résumant les données Yc et Yl : alors que chaque ligne (resp. chaque colonne) était résumée par un ensemble de valeurs "0" pour les classes auxquelles elle n'appartenait pas, et une valeur "1" pour sa classe, on peut ici la résumer par des valeurs qu'on ne contraint pas à être des "0" ou des "1" ; ces valeurs constituent des genres de notes, ou d'indicateurs (fig. 9). Si cette ligne intervient dans un seul concept, elle n'aura qu'une seule valeur différente de 0, plus ou moins forte selon son degré de participation au concept. Comme on l'a vu plus haut, elle peut intervenir dans plusieurs concepts, mais elle peut également être atypique par rapport à tous les autres éléments du tableau, donc n'avoir que des valeurs faibles ou nulles sur l'ensemble des concepts.

Figure 9 -- Tableau résumé "nuancé"
(cas de l'analyse factorielle,
ou de la classification floue
et recouvrante.
Plusieurs méthodes d'analyse des données fournissent des résultats qui se rapprochent de cette forme :

Figure 10 -- Tableau résumé "semi-nuancé"
(cas de la classification recouvrante).
L'informatique graphique n'existant pas à l'époque, cette méthode ne put pas tirer parti de toutes ses potentialités (elle se contentait de créer de nouveaux mots-clés correspondant aux classes trouvées) et fut abandonnée. J'avancerai également une autre hypothèse pour cette désaffection, sur une base plus culturelle : le terrain des sciences humaines et de leurs méthodes est le plus souvent perçu comme étranger, voire dangereux, par les professionnels de l'informatique et de la documentation. Ce n'est sans doute pas un hasard si l'analyse des données documentaires n'a connu un développement réel que là où elle pouvait s'appuyer sur une problématique de sciences humaines, principalement en France et aux Pays-Bas, et que ses utilisations opérationnelles actuelles se situent dans le domaine de l'évaluation scientométrique et la veille technologique - tous domaines où la part de l'interprétation des résultats est prépondérante, et où les auteurs d'études n'hésitent pas à procéder à de multiples aller-retours entre 1) la constitution du corpus à analyser, et 2) le choix et le paramétrage des méthodes d'analyse, avant de stabiliser leur interprétation des résultats.
Le tableau des résultats commence à ressembler à notre tableau idéal de description de concepts ; seule la dernière contrainte contrevient à notre principe "naturel" selon lequel certaines lignes peuvent n'appartenir à aucun concept (et réciproquement qu'une même ligne peut appartenir fortement à plus d'un concept). Ce n'est pas des probabilités que nous faisons apparaître, mais des certitudes : par exemple qu'un mot a deux sens différents dans deux contextes différents !

Figure 11 -- Allure des axes d'analyse factorielle.
Ceci correspond parfaitement à notre idéal de description de concepts, et ce n'est sans doute pas un hasard si Thurstone, un théoricien majeur de l'analyse factorielle dans les années 1930-40, a posé les principes de définition de la "structure simple" d'un résumé de tableau de données qui s'accordent tout à fait avec cet idéal, et ont pu être approchés au mieux par les analyses factorielles obliques.
Ces méthodes n'ont eu que peu de succès jusqu'à
présent sur le "marché" des méthodes d'analyse des
données : leurs algorithmes sont complexes et ne conviennent en
pratique qu'à des tableaux de dimensions réduites, alors que
c'est précisément sur les tableaux de grandes dimensions qu'elles
pourraient déployer leurs avantages par rapport à leurs consoeurs
"orthogonales". En effet elles pourraient y cumuler les avantages des
classifications, à savoir le côté local de
l'opération consistant à grouper des éléments
ressemblants, avec le côté progressif, nuancé, de la
représentation par valeurs factorielles continues. Elles furent
développées, pour leur malheur, dans le contexte très
spécialisé de l'exploitation des batteries de tests
psychologiques, et liées de ce fait à des théories parfois
tombées en désuétude... Enfin trop de variantes et
paramétrages étaient possibles, dont la compréhension
nécessitait des connaissances mathématiques poussées,
désorientant les utilisateurs de bonne volonté.
Au contraire, le marché des méthodes d'analyse des données
a consacré un nombre restreint de "hits", dont l'utilisation
présente souvent un caractère "presse-bouton". Comme souvent,
beaucoup d'appelés et peu d'élus : un milieu de recherche
que j'estimerai au débotté à un millier d'individus, actif
et en renouvellement permanent depuis plus d'un demi-siècle, a produit
des milliers de méthodes et de variantes (au moins une par
chercheur !) ; une cruelle sélection naturelle n'a retenu
qu'une demi-douzaine de méthodes d'usage courant :
Cette parenthèse sur l'univers impitoyable de la recherche étant close, reprenons nos considérations sur l'extraction de concepts à partir des données. Nous n'avons pas discuté un point important : le nombre de concepts extrait d'un tableau considéré.
Bien que certains psychologues aient émis l'hypothèse qu'il pouvait exister un niveau privilégié d'abstraction, menant à des découpages catégoriels "optimaux", il est admis qu'une même réalité peut être découpée plus ou moins finement suivant le "niveau de perception" auquel on se place : ce qui était distinct vu de près se confond vu de loin ; ceci concerne l'intellect autant que la vision, puisque l'intellect "accommode à" sa façon, depuis le point de vue de Sirius jusqu'à l'attention la plus fine portée aux détails, selon les circonstances. Ce qui pourrait se traduire dans notre formalisme de la façon suivante :
Quelques-unes des méthodes citées plus haut comportent implicitement un tel paramètre, mais la plupart ne l'exploitent pas ; seules certaines méthodes de classification dites "de densité" en font usage, et nous y reviendrons plus bas.
Lorsque le recueil de données procède, comme dans le cas des bases de données documentaires, d'une interaction entre les capacités d'êtres humains (ici les ingénieurs documentalistes), qui attribuent des mots aux choses et l'évolution de ces choses (ici, le mouvement des sciences et des techniques), deux points de vue sont concevables :
Comment
extraire des concepts ?
Tableau de données et métaphore du nuage de points.
Disposer des données en tableaux est une des plus vieilles techniques d'ingénierie de la connaissance", amenant l'esprit à saisir comme un tout ce qui était un ensemble de souvenirs disparates, et à rendre comparables ces observations [Goody 1979] -- à noter qu'il existe d'autres structures fondamentales comme les arbres, les hiérarchies, les listes, qui trouvent leur descendance moderne dans les tendances dominantes de l'informatique et de l'intelligence artificielle (langage LISP, représentations arborescentes des connaissances, ...).
En ce qui concerne les tableaux, l'apparition de l'ordinateur permet de passer à un niveau supérieur de synthèse : comment représenter synthétiquement un très grand tableau ?
Comment visualiser, rendre sensible, la densité d'un nuage de
points ?Réponse : en "épaississant", en "empâtant" chaque point du nuage, c'est-à-dire en déposant successivement des "pâtés" élémentaires de même forme dans le voisinage de chaque point. Un croquis dans le cas le plus simple qui soit, celui du nuage à une seule dimension, rendra les choses limpides. La fig. 12-1 montre notre nuage de 8 points étalé sur la seule direction de l'espace que nous l'ayons autorisé à investir. Notre oeil perçoit des zones de tassement plus serrées des points, et d'autres de desserrement. Déposons, centré sur chaque point, un monticule élémentaire de forme donnée par la fig. 12-2 : l'accumulation de ces monticules créera un "paysage" dont les monts et les vaux correspondront, ô surprise, à notre perception des zones de tassement et d'éclaircissement des points ! En répétant l'opération avec d'autres formes de "pâtés" élémentaires, on peut faire deux remarques :

Figure 12-1 -- "Nuage de points" unidimensionnel.

Figure 12-2
La largeur du pâté aura de l'influence sur le nombre d'ondulations que l'on trouvera dans le paysage : une grande largeur "lissera" l'ensemble pour ne plus former qu'une seule montagne (fig. 12-3) ; une faible largeur exhibera, à la limite, autant de mamelons élémentaires que de points du nuage (fig. 12-4). On retrouve ici notre notion de niveau de perception : vu de loin, le nuage de points se résume à un seul paquet de points ; vu à la loupe, chaque point est éloigné de tous les autres. La largeur du pâté est donc un paramètre de "zoom" qui permet de focaliser notre attention sur des détails plus ou moins fins, et faire varier le "grain" de la description.
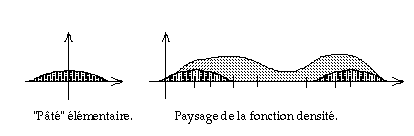
Figure 12-3

Figure 12-4
Revenons à notre but de recherche de "concepts" au sens défini plus haut, c'est-à-dire à la constitution de tableaux de nombres de dimension très réduite par rapport à celle du tableau originel des données. L'idéal serait de pouvoir attribuer à chaque ligne de ce tableau un indicateur de proximité, d'appartenance à une (ou plusieurs) des collines du paysage de densité que nous aurons défini. Mais comment faire si nous sommes dans un grand nombre de dimensions, et non plus sur une seule comme dans notre petit exemple ?
Pour nous simplifier encore une fois la vie, nous allons décréter que nous nous contentons d'un nuage de points simplifié dont tous les points sont à la même distance de l'origine. En effet le nombre de descripteurs présents dans une ligne du tableau nous importe peu, seul nous importe le fait que des descripteurs sont communs à des lignes de données. De cette façon certaines lignes comporteront par exemple, outre les valeurs 0, des valeurs 0,25 pour les descripteurs présents, alors que d'autres, où les descripteurs présents sont beaucoup plus nombreux, se verront attribuer la valeur 0,15. C'est le profil qui nous intéresse, pas les valeurs quantitatives ! Cette opération dite de normalisation de chaque ligne de donnée nous donne un nuage de points tous situés à la surface d'une sphère, ou plutôt d'une hypersphère puisque le nombre de dimensions de notre espace est bien supérieur à 3... N'essayez pas de vous imaginer cette monstruosité géométrique, c'est impossible (sauf si vous êtes un mutant : écrivez-moi, vos talents m'intéressent...) ; contentez-vous de vous représenter des points bien sagement disposés à la surface d'une sphère banale (fig. 13), et sachez que tout ce que nous dirons au sujet de ces points pourra s'extrapoler à un nombre indéterminé de dimensions sans autre forme de procès. En particulier qu'on pourra définir une notion de densité semblable à celle vue précédemment en "empâtant" chaque point du nuage, ou plutôt ici chaque axe reliant le point au centre de la sphère.

Figure 13
Le grand avantage de l'opération, c'est que l'on récolte enfin les indicateurs d'appartenance plus ou moins forte à un groupe que nous cherchions : à partir du moment où un "groupe flou", un "type", sera caractérisé par son axe de plus grande densité -- étant données la forme et la largeur du "pâté élémentaire" choisi --, la valeur de la simple projection d'un point du voisinage sur cet axe constituera cet indicateur de "saillance". Pour les voisins immédiats de cet axe prototypique, la saillance sera proche de 1, pour les points éloignés elle sera voisine de 0, avec tous les intermédiaires possibles. On montre -- prodige de la géométrie multidimensionnelle -- que ces contrastes sont d'autant plus forts que le nombre de dimensions est élevé. A noter que notre tas-élémentaire-dont-l'accumulation-produit-le-gros-tas sera caractérisé ici par un profil axial (fig. 14-1)$$$$$$$$$$, et sa demi-largeur par un angle qo ; la figure 14-2 $$$$$$$$$$ fournit une autre représentation, plus simple, de ce même tas élémentaire.

Figure 14
La méthode proposée : "empâtement" du nuage de points, puis mise en évidence de ses caractéristiques, n'est pas nouvelle. Mais elle avait été proposée dans le cadre de méthodes de classification "dures", en tout ou rien, où la représentation en résultant était l'attribution d'un numéro de classe et d'un seul à chaque ligne du tableau [ex. : Trémolières 1979, Emptoz et al. 1981, + bonne synthèse dans Chandon et Pinson 1981]. Bien qu'elles semblent avoir eu peu de succès, leurs avantages n'étaient pas nuls à mon sens :
Peut-être une des explications à leur faible pénétration est-elle à chercher dans le changement de point de vue qu'elles impliquaient par rapport à la plupart des méthodes d'analyse de données :
Il est paradoxal de constater que c'est le premier problème qui est le plus ardu à résoudre mathématiquement : en dehors du cas de certaines analyses factorielles -- analyse en composantes principales et analyse des correspondances [Bouroche, Saporta 1983, Cibois 1983] -- pour lesquelles il existe une solution exprimable analytiquement (recherche de valeurs propres et vecteurs propres d'une matrice, en termes techniques), il est pratiquement exclu d'espérer atteindre l'optimum absolu. Au contraire le caractère local, c'est-à-dire lié à un voisinage de taille fixe, de méthodes de densité permet de converger facilement vers un ensemble de pics locaux significatifs. Nous avons également en vue une variante dite incrémentale de nos algorithmes -- ce qui signifie qu'à chaque nouvelle ligne de donnée présentée la solution complète est mise à jour comme si on avait refait l'analyse sur toutes les données -- variante qui permettrait d'atteindre l'ensemble des pics, donc un optimum absolu, et résoudrait ainsi complètement le problème de ne "rater" aucun optimum local (moyennant quelques restrictions mineures).
Comment procéder ?
Arrivés à ce point, résumons-nous : il nous suffit de deux éléments -- un tableau de données et une fonction élémentaire d'empâtement -- pour définir implicitement un paysage de fonction densité. Nous voudrions connaître les points remarquables de ce paysage, à savoir les maxima locaux, alors qu'il n'est défini qu'implicitement. Que faire ? Deux pistes s'ouvrent à nous :
Exemple
d'une base de données scientifique.
Apr&ggrave;s ce long développement très théorique, et avant de nous pencher plus avant sur les méthodes annoncées, il est grand-temps de raccrocher votre réflexion à quelques éléments un tant soit peu concrets ; nous décrirons en l'occurrence une interface pour parcours de base de données documentaire fondée sur ces principes.
Principes
de conception d'un outil de parcours ("browser") idéal :
Pour qu'un voyageur se situe à tout moment sur le terrain et décide de son chemin, il doit disposer à la fois d'outils d'orientation globale (carte, boussole..) et d'une vue locale des lieux. Nous nous appuierons sur cette métaphore pour décrire notre système documentaire idéal, dont des réalisations approchées commencent à voir le jour (cf. [Lelu, Tisseau-Pirot 94], et [Grivel, François 95] dans ce même numéro) .
La carte globale (cf. fig. 15-1) donne lieu à plusieurs utilisations :

Figure 15-1 -- Carte globale d'une base documentaire (source : ANDRA).
Figure 15-2 -- Axes de parcours locaux d'une base documentaire (source : ANDRA)
pour le thème
"Géotechnique du sel" =
listes ordonnées des
mots-clés
et des documents typiques du thème.
Si un item de la base (document, terme, item supplémentaire) était déjà sélectionné au moment de l'ouverture d'un type de fenêtre correspondant, cette fenêtre s'ouvrira autour de la partie de la liste contenant cet item, qui sera alors distingué par un signe ou une couleur particulière.
L'usager peut parcourir ces listes de façon classique au moyen d'"ascenseurs", ce qui peut lui suggérer des items qui lui paraissent pertinents et dont il ignorait jusque là l'existence dans la base. S'il en sélectionne un par cliquage, deux "zooms" en sens inverse lui sont proposés :
Nous avons développé l'idée d'une symétrie, d'une dualité entre le rôle des descripteurs et celui des objets décrits ; cette notion, issue de la symétrie formelle entre les lignes et les colonnes d'un tableau de description, est familière aux statisticiens de l'école française d'analyse des données [Benzécri 81]. Elle découle de la proposition : "à chaque objet documentaire est associé un ensemble de descripteurs, à chaque descripteur est associé un ensemble d'objets documentaires". Depuis le début de notre recherche nous avons pris le parti de tirer jusqu'au bout les conséquences de cette dualité dans le domaine des bases documentaires de photos, en concevant et réalisant des dialogues totalement symétriques d'accès à partir des mots-clés aussi bien qu'à partir des images ; cet exercice de changement de perspective s'est révélé fructueux en tant qu'heuristique de conception de dialogues homme-machine, ...mais également encourageant sur le plan opérationnel, comme l'a montré en 1985 l'évaluation ergonomique de notre maquette ICONOTRON, et plus récemment notre interface NEURONAV [Lelu, Tisseau-Pirot 94], où cette symétrie a été étendue aux thèmes extraits.
Insistons sur le fait qu'il est possible de déterminer les documents proches d'un terme donné, ou proches d'un document donné, dans un seul contexte - et non pas dans la totalité de la base documentaire, comme le font les techniques d'expansion de requête ou de propagation d'activité ! Ici l'expansion de requête est contextuelle, et cette propriété est particulièrement utile dans le domaine linguistique, où il est bien connu qu'un mot peut prendre plusieurs sens différents suivant les contextes. Ce qui n'exclut pas que d'autres domaines d'application puissent partager la même caractéristique : un même symptôme médical, par exemple, peut renvoyer à des pathologies très différentes.
Réalisation
d'une maquette d'interface de système documentaire basée sur ces
principes :
Ces travaux se poursuivent actuellement à l'INIST (cf. [Grivel, François 95] dans ce même numéro), et pallient les manques constatés lors des évaluations : rapidité, prise en compte des noms d'auteurs et des sources bibliographiques pour caractériser les axes et activer la carte (fonction "affichage de listes d'items supplémentaires" vue plus haut), ...
Un
aperçu des algorithmes utilisés.
1 - Algorithmes
neuronaux.
Le courant de recherche sur les modèles dits "neuronaux" regroupe un ensemble très hétérogène de problèmes à résoudre et de façon de les résoudre. C'est plus une bannière, un mot d'ordre, qu'un réel domaine scientifique homogène. Néanmoins tous les modèles envisagés partagent en commun au moins cette caractéristique : un neurone est une cellule élémentaire -- et même simpliste -- dotée de nombreuses entrées et d'une seule sortie ; à chaque entrée est associée une valeur dite "poids synaptique" ; quand on applique à cette cellule un ensemble de valeurs d'entrée -- un "vecteur-entrée" elle produit une valeur de sortie fonction de ces entrées et des valeurs synaptiques internes, ou vecteur-poids synaptique (pour faire plus "bio", certains parlent d'"activités" plutôt que de valeurs numériques, mais le résultat est le même...).
La plupart des modèles prévoient des synapses qui peuvent se modifier au cours du temps, en particulier au fil de l'arrivée de vecteurs d'entrée extérieurs, selon une loi dite d'apprentissage. C'est l'auto-modification de leurs poids qui constitue le processus d'apprentissage d'un ensemble de neurones ou réseau neuronal (notez que la sortie des uns peut constituer l'entrée des autres, et que la topologie de ces réseaux n'a d'autre limite que l'imagination de leurs auteurs... et l'adéquation des solutions qu'ils apportent !). L'ensemble des poids d'un réseau neuronal, résultat de l'intégration de toute son expérience passée, constitue sa mémoire, dans un sens fruste et très mécaniste, mais plausible biologiquement.
Puisqu'un neurone peut être représenté par un vecteur, à savoir son vecteur-poids synaptique, j'en reviens à nos moutons, ou plutôt à nos axes à la surface d'une hypersphère : pourquoi ne pas considérer chaque axe comme un neurone, qu'une loi d'apprentissage ferait évoluer au fil de l'arrivée des données, le plus rapidement possible, vers une position intéressante correspondant par exemple à un maximum de densité de points ? Il suffit que la loi en question tende en moyenne à déplacer le neurone dans le sens montant de la pente du paysage (fig. 13-2), et le tour est joué, non sans avoir "semé" abondamment des neurones au hasard à la surface de l'hypersphère en début de processus. Ce serait bien le diable si au bout d'un bon nombre de passages sur les données la plupart des maxima conséquents ne se retrouvent pas occupés par un ou plusieurs neurones !
Pour améliorer l'algorithme, c'est-à-dire avoir moins de neurones à utiliser, donc à loger et à mettre à jour dans la mémoire de l'ordinateur, on peut utiliser des heuristiques, c'est-à-dire des procédures non rigoureuses (par exemple des interactions entre neurones, des "inhibitions" ou des "excitations" en termes plus biologiques) qui forceront chaque neurone à occuper un sommet différent.
Un premier algorithme, que nous avons nommé méthode des K-means axiales en référence à la méthode connue de classification automatique dont il constitue une variante, présente l'avantage de cumuler -- pour une fois -- une exécution très rapide avec une occupation très faible d'espace mémoire, ce qui le rend apte à analyser nos colossales bases documentaires avec nos moyens de calcul actuels. Par contre -- il n'y a pas de miracle --, il est sensible aux paramètres d'initialisation, ce qui oblige à réaliser par prudence plusieurs analyses pour un même corpus, et à n'interpréter que les "formes fortes" ou thèmes communs émergeant dans tous les passages, les autres thèmes pouvant être fugaces ou de composition instable. Pour la description de cet algorithme, nous renvoyons le lecteur à l'article de Luc Grivel et Claire François dans ce même numéro.
La deuxième approche a été proposée précisément pour pallier les aspects insatisfaisants des algorithmes de type "centres mobiles" ; en effet, pourquoi se fatiguer à interpréter des résultats, si ceux-ci varient de façon plus ou moins arbitraire au gré des paramètres d'initialisation ? Il nous faut une méthode dégageant des représentations stables et reproductibles (en d'autres termes : dégageant d'emblée les formes fortes) : la notion de paysage de densité, qui présente un tel caractère de stabilité, une fois fixé le paramètre de finesse d'analyse, nous paraît un bon principe de base pour obtenir de telles représentations. Ensuite, cette base étant acquise, on pourra toujours discuter le type de fonction d'empâtement permettant de constituer le paysage, ainsi que la nature de la représentation synthétique qu'on en donnera :
La recherche sur toutes ces questions, esquissée par quelques travaux sur les méthodes de densité en classification et sur les généralisations "locales" de l'ACP, n'en est à mon sens qu'à ses débuts. Pour ma part, je présenterai maintenant les choix que j'ai opéré dans un premier travail intitulé "analyse en composantes locales" par référence à l'ACP dont il constitue en un certain sens une extension.
Analyse
en Composantes Principales :
L'indicateur qu'on cherche à maximiser en ACP, sa fonction objectif, s'appelle l'"inertie" du nuage de point. En d'autres termes, à tout axe passant par l'origine des coordonnées -- en général le centre de gravité du nuage -- on associe une valeur constituée en sommant les carrés des projections des points du nuage sur cet axe. Il a été démontré depuis longtemps que le paysage de cette fonction objectif a des propriétés particulières : il ne comporte qu'un seul maximum et un seul minimum, dénommés respectivement première et dernière composante principale pour des données à trois dimensions, on peut imaginer un paysage ressemblant à un ballon de rugby aplati. En dehors des axes correspondant à ces deux points évidents, il existe d'autres axes remarquables : ils correspondent à des "méplats", ou zones intermédiaires où la fonction objectif est stationnaire - par exemple l'axe correspondant au renflement intermédiaire de notre ballon de rugby aplati.
Il a été démontré -- sortilège de l'algèbre appliquée à la géométrie -- que, quel que soit le nuage de points et le point origine considéré, ces axes (intermédiaires ou pas) étaient tous perpendiculaires entre eux ; résultat qui n'a rien d'intuitif, surtout dans un espace à plus de trois dimensions ! En termes techniques, les hauteurs de tous ces points remarquables du paysage d'inertie s'appellent les valeurs propres, et les directions sur lesquelles ils sont situés les vecteurs propres, ici dénommés aussi facteurs ou composantes principales.
La représentation factorielle du nuage de points consiste habituellement en sa mise à plat, sa projection sur les deux "meilleures" dimensions : chaque point du nuage est représenté à partir de ses coordonnées sur les deux premiers axes factoriels (correspondant aux deux points remarquables de plus grande hauteur du paysage d'inertie) ; c'est cette projection du nuage sur deux dimensions qui résume le mieux la position relative des points dans l'espace multidimensionnel ; elle est fixe, stable, et indépendante des contingences du calcul informatique des vecteurs propres, ou de l'ordre de lecture des données.
Analyse
en Composantes Locales :
Nous nous sommes inspirés de ce schéma pour définir notre méthode d'Analyse en Composantes Locales (ACL) : au lieu de définir la fonction objectif par la somme des carrés des projections du nuage de points, nous la définissons par la somme des carrés des projections tronquées. La projection tronquée d'un point du nuage sur un axe passant par l'origine est une grandeur positive ou nulle qu'on obtient en retirant à la valeur de cette projection une quantité fixe, quantité qui constitue précisément notre paramètre de finesse d'analyse : plus ce paramètre est proche de 1 (n'oublions pas que notre nuage est situé sur une sphère de rayon 1), et plus le paysage d'inertie locale, partielle, sera accidenté. Il est facile de montrer que ce paysage est constitué par l'accumulation d'autant de "pâtés" élémentaires que de points du nuage, chaque pâté étant d'autant plus étalé que notre paramètre de finesse d'analyse est faible. On reconnaît le schéma général d'analyse exposé plus haut, où le but du processus est de localiser les points du paysage les plus représentatifs de monticules, monticules créés dans les zones de forte densité du nuage. Ici nous conservons l'avantage mentionné pour l'ACP d'un paysage fixe et indépendant des contingences du calcul, pour une valeur fixée du paramètre de finesse d'analyse.
Le seul problème est que pour l'instant ce paysage n'a qu'une existence virtuelle, et qu'il nous faut trouver des procédures de calcul opérationnelles pour localiser ses points remarquables : c'est ici qu'entrent en scène nos modèles de neurones.
En effet, on peut considérer un neurone comme une "machine à calculer la projection" d'un vecteur-donnée sur un vecteur-poids interne : ce vecteur-poids définit une direction issue de l'origine des axes, et plus un vecteur-donnée est proche de cette direction (c'est à dire plus le profil d'une ligne de tableau présentée au neurone ressemble à son profil interne de poids), plus la valeur de sortie du neurone est élevée. De façon plus précise, notre modèle de neurone calcule la projection tronquée du vecteur-entrée présenté, ce qui constitue sa "fonction de transfert", c'est-à-dire le processus permettant de calculer sa sortie à partir d'un profil d'entrée. Reste à doter ce neurone d'une loi de modification de ses poids, dite loi d'apprentissage, qui lui permette de pointer vers une position intéressante au fur et à mesure qu'on lui présente l'ensemble des données une première fois, puis une deuxième, etc., jusqu'à stabilisation.
J'ai montré [Lelu 93] qu'une loi d'apprentissage très simple et classique dans le domaine des réseaux neuronaux, dite loi de Hebb, selon laquelle la variation d'un poids est proportionnelle à la fois à l'entrée agissant sur ce poids et à la sortie du neurone, permettait d'arriver à un tel résultat. En effet quand on initialise les poids d'un neurone à des valeurs arbitraires, puis quand on le soumet successivement à chaque vecteur-donnée pour le calcul de sa sortie et de la variation de ses poids, le vecteur-poids du neurone finit par pointer dans la direction d'un sommet du paysage de densité, plus précisément du sommet le plus proche de sa direction de départ.
Notons que jamais il n'a été nécessaire de calculer explicitement le paysage d'inertie partielle (ou densité), et que celui-ci ne constitue qu'une simple explication conceptuelle de la raison pour laquelle un neurone finit par se stabiliser dans telle direction plutôt que dans telle autre ! Si le point de départ du neurone souffre par définition d'arbitraire, le point d'arrivée, lui, est parfaitement défini, et est indépendant de l'ordre de présentation des lignes du tableau de données.
Nous venons de voir comment un neurone converge vers le sommet le plus proche de sa direction de départ. Mais ce qui nous intéresse en fait est de peupler tous les sommets du paysage avec un neurone chacun. Ceci est possible grâce à une heuristique, c'est-à-dire une procédure non rigoureuse, que je ne décrirai pas ici, et qui permet d'investir les principaux sommets (les plus hauts), ou l'ensemble de ceux-ci quand on dispose d'une quantité suffisante de mémoire vive.
Les choix que j'ai effectué pour caractériser le paysage de densité, en bâtissant cet algorithme dénommé Analyse en Composantes Locales, sont critiquables et critiqués [Courtial**] : un "pic" caractérise bien une tendance locale forte, mais mal l'ensemble du massif sous-jacent. Ils n'ont d'autres prétentions que d'être une première approche vers la caractérisation d'un paysage de densité, fixe pour une valeur donnée du paramètre de finesse d'analyse, et indépendant de l'initialisation de l'algorithme ainsi que de l'ordre de présentation des données.
Limites
de notre modèle d'émergence des concepts. Vers un
dépassement de ces limites ?
Bien que l'idée de faire émerger des concepts à partir du traitement automatique, sans a priori, d'un simple tableau de nombres puisse paraître simplette, elle n'en conduit pas moins à mettre à jour quelque chose qui ressemble fort à du sens, de la signification, quand on analyse par exemple des ensemble de textes à qui l'on a fait subir les derniers outrages : "désyntaxisé", "normalisé", chaque texte est réduit à une bouillie informe de mots juxtaposés en vrac ! Pourtant, comme le soulignent Ludovic Lebart et André Salem [Lebart & Salem, 1994], la sémantique, a priori apanage noble de l'intellect humain, se dégage par un traitement du plus bas niveau qui soit, ce qui a le don d'exaspérer certains linguistes et cogniticiens plus portés par goût sur la logique et les systèmes formels que sur les statistiques...
Toutefois nous concéderons bien volontiers que le sens, les concepts que l'on dégage par nos méthodes rendent bien compte "de quoi parlent les textes" -- le problème de base de quiconque recherche de l'information --, mais sont muettes sur "ce qu'ils en disent", qui pourrait s'appliquer à un processus "intelligent" déclenchant une action ! Nous ne contestons pas que le modèle de micro-monde présenté au début et incarné par un tableau rectangulaire de données comporte un certain nombre de limites intrinsèques :
Signalons que certaines méthodes d'analyse des données et de reconnaissance des formes introduisent des contraintes de "contiguïté" entre les capteurs donnant lieu aux observations, ou entre les observations, tenant ainsi compte d'un espace substrat donné a priori [Lebart 69][Bénali, Escoffier 90].
Là aussi il faut mentionner que certaines méthodes statistiques d'analyse des séries chronologiques, certains modèles neuronaux commencent à savoir traiter des "formes" spatio-temporelles, des séquences événements : par exemple des réseaux neuronaux propagent une activité d'entrée avec des retards modulables, sans extinction immédiate, ce qui permet à ces réseaux d'intégrer leur activité actuelle aux activités antérieures [ex. : Gjerdingen 1992].
Par contraste de nombreux travaux en reconnaissance des formes, ou certains modèles neuronaux de vision artificielle, détectent des formes indépendamment de leurs déformations (rotation, translation, masquage...) [Haken 89]. Ceci est une première étape vers des systèmes susceptibles de détecter dans leur environnement des objets invariants mobiles, ou la variation de leur propre position par rapport à un environnement fixe.
Pour leur part les modèles d'optimisation de trajectoire en robotique, de contournement d'obstacles comportent une fonction objectif à optimiser sur l'ensemble du mouvement, et des capteurs rendant compte à la fois du "point de vue de l'effecteur", et de l'état du monde - ce qui se traduit concrètement par des mouvements souples et lissés, aux antipodes de l'archétype du robot aux mouvements saccadés... Certains réseaux neuronaux résolvent des problèmes difficiles, tels que faire tenir en équilibre une longue tige sur un chariot roulant, ou faire accoster une semi-remorque à reculons vers un quai de déchargement en partant d'une position quelconque [Bourret & al. 91] ! Malgré leurs exploits ces exemples sont loin de suggérer l'existence d'un sujet. Mais on trouve aussi des modèles ultra-simplifiés de micro-mondes formés par exemple de nourriture et d'un "blob" optimisant sa survie : des stratégies diversifiées et non-triviales ont pu être observées au cours des simulations en fonction de la quantité et de la disposition spatiale de la nourriture [Patarnello, Carnevali 89]...
On pourrait considérer que les modèles neuronaux très répandus d'"apprentissage avec superviseur" simulent une interaction sociale très simple, où le maître tape sur les doigts de l'élève quand sa réponse est erronée ; ils n'en arrivent pas moins à s'attaquer à des problèmes non triviaux, comme reconnaître si une suite de 1 et 0 possède un nombre pair ou impair de 1 [Fogelman & al. 87].
Mu par des ambitions plus vastes, le courant de recherche dit "artificial life" explore (entre autres) des situations d'interaction dans des "sociétés d'insectes" schématiques, et montre l'émergence de comportements collectifs "intelligents", ou du moins adéquats, à partir d'un grand nombre d'individus à comportement et communication des plus sommaires [Langton 89].
En attendant, étonnons-nous encore une fois de constater qu'à partir de notre modèle de micro-monde d'une pauvreté effarante, on parvient à faire naître du sens humainement acceptable. Il est le plus souvent admis que si la sémantique est le domaine réservé des plus hautes fonctions intellectuelles humaines, la syntaxe du langage ("la grammaire", disait-on autrefois) est d'une nature beaucoup plus mécanique, simulable par un ensemble de règles rigides appliquant les canons de la logique formelle. La démarche classique de l'intelligence artificielle nous a habitué à des simulations "mécaniques" de raisonnements à partir d'ensembles de concepts dits de haut niveau pourvus de relations logiques et syntaxiques entre eux.. Le programme standard de l'intelligence artificielle d'inspiration logicienne est d'"expliquer" de plus en plus de sémantique par de la syntaxe.
Ne serait-on pas tout aussi fondé à renverser le point de vue et soutenir que ce sont plutôt les opérations de mise en ordre du monde, d'abstraction au sens le plus général du terme, de conceptualisation, qui sont les opérations de bas niveau ? De même que les neurones de la rétine "empâtent" (convoluent, en termes techniques) les images qu'ils traitent [Petitot 1990], on peut supposer que certains neurones (du cortex ?) "empâtent" les flux d'informations linguistiques qui les atteignent pour en dégager les faisceaux de traits significatifs, les concepts [3] - et dans ce cas leur fonction est encore plus simple que celui de leurs homologues de la rétine, puisqu'ils n'ont pas à tenir compte d'un espace substrat physique comme celui des images !
Au contraire l'existence d'une syntaxe suppose l'existence de l'action, de buts, d'intentions de la part d'un sujet existant, et donc de structures neuronales beaucoup plus complexes et de haut niveau, au sujet desquelles on sait très peu de choses aujourd'hui, même si certains pionniers [Varela 1989] ouvrent la voie et commencent à définir des concepts pertinents ("autopoïèse"...).
Nous venons d'esquisser les réponses que des travaux souvent, mais pas exclusivement, d'inspiration connexionniste commencent à offrir aux divers degrés de difficulté listés plus haut ; ces réponses sont partielles, nulle cohérence ne se dégage encore entre elles, mais cette liste n'avait pour but que de vous illustrer l'idée que les limites de notre approche seront un jour être transcendées. Les quelques références citées sont loin d'être exhaustives : le plus souvent des dizaines de travaux pourraient illustrer chaque thème.
Conclusion
Notes
Annexe
- "Pour en savoir plus" :
. Ouvrages, articles non spécialisés :
BERTIN, J. - La graphique et le traitement graphique de l'information - Flammarion, Paris, 1977
BOUROCHE, J.M. ; SAPORTA, G. - L'Analyse des Données - Que sais-je ?, PUF, Paris, 1983
BENZÉCRI, J.P. et coll. - Pratique de l'Analyse des Données : Linguistique et Lexicologie - Dunod - Paris - 1981
CALLON, M. ; COURTIAL, J.P. - La Scientométrie - Que sais-je ?, PUF, Paris, 1993
CATHELAT, B. - Panorama des styles de vie - Ed. des Organisations, Paris, 1990
CHANDON, J.L. ; PINSON, S. - Analyse typologique - théorie et applications - Masson, Paris, 1981
CIBOIS, P. - L'analyse factorielle - Que sais-je ?, PUF, Paris, 1983
COURTIAL, J.P. - Introduction à la scientométrie : de la bibliométrie à la veille technologique - Anthropos, Paris, 1990
DUBOIS, D. (dir.) - Sémantique et cognition - Catégories, prototypes, typicalité - Ed. du CNRS, Paris, 1991
DUCLOY, J. ; LELU, A. - "Neurodoc : construction d'hyper-documents à l'aide de procédés neuronaux" - Journées Génie Linguistique 91 (Versailles), EC2, Nanterre, 1991
GOODY, J. - La logique de l'écriture - Armand Colin, Paris, 1986
GRIVEL, L. ; FRANÇOIS, C. - "Une station de travail pour classer,
cartographier et analyser l'information bibliographique dans une perspective de
veille scientifique et technique" - Les Cahiers Solaris, Presses Universitaires
de Rennes, Nº 2, 1995
Disponible dans Solaris W3 nº 2
LEBART, L. ; SALEM, A. Salem - Statistique textuelle - Dunod, Paris, 1994
LELU, A. ; FRANÇOIS, C. - "Automatic generation of hypertext links in information retrieval systems" - communication au colloque ECHT'92 (Milan), D. Lucarella & al. eds., ACM Press, New York, 1992
LELU, A. ; TISSEAU-PIROT, A.-G. - "Vers une nouvelle génération de systèmes documentaires évolués : une chaîne expérimentale de génération automatique d'hypertextes" - La Tribune des Industries de la Langue, Nº 15, OFIL, Paris, 1994
PETITOT, J. - "Le physique, le morphologique, le symbolique : remarques sur la vision" - Revue de synthèse, série générale, tome CXI, Nº 1-2, pp. 139-184, 1990
VARELA, F.J. - Autonomie et connaissance, essai sur le vivant - Ed. du Seuil, Paris, 1989
. Articles spécialisés :
BÉNALI, H. ; ESCOFFIER, B. - "Analyse factorielle lissée et analyse factorielle des différences locales", Revue de Stat. Appliquée, Vol. 38, Nº 2, pp. 55-76, 1990
BOURRET, P. ; REGGIA, J. ; SAMUELIDÈS, M. - Réseaux neuronaux - pp. 200-205, Teknea, Toulouse, 1991
BURTSCHY, B. ; LEBART, L. - "Contiguity Analysis and Projection Pursuit"- Applied Stochastic Models and Data Analysis, R. Gutierrez & M.J. Valderrama eds., World Scientific, 1991
CAUSSINUS, H. - "Projections Révélatrices"- Modèles pour l'analyse des données multidimensionnelles, dir. J.J. Droesbeke et al., Economica, Paris, 1992
EMPTOZ, H. ; HASHOM, A. ; TERRENOIRE, M. - "Fonctions structurantes et classification automatique" - Actes de : Reconnaissance des formes et intelligence artificielle - J.P. Haton, ed., AFCET, Paris, pp. 449-457, 1981
ESCOFFIER, B. - "Analyses Factorielles et Distances répondant au critères d'équivalence distributionnelle", Revue de Stat. Appliquée, Vol. 26, Nº 4, 1978
FOGELMAN, F. ; GALLINARI, P. ; LE CUN, Y. ; THIRIA, S. - "Automata Networks and Artificial Intelligence", Automata Networks in Computer Science, Theory and Applications, pp. 133-186, Manchester University Press, 1987
GJERDINGEN, R.O. - "Learning Syntactically Significant Temporal Patterns of Chords : A Masking Field Embedded in a ART3 Architecture" - Neural Networks, vol.5, pp. 551-564, 1992
HAKEN, H. - "Duality between pattern recognition and pattern formation in synergetic systems" - Neural networks from models to applications, L. Personnaz, G. Dreyfus eds., pp. 449-459, IDSET (ESPCI), Paris, 1989
LANGTON, C.G. ed. - Artificial Life - Addison-Wesley, New York, 1989
LEBART, L. - "Analyse statistique de la contiguïté" - Publications de l'ISUP, vol. 18, pp. 81-112, Paris, 1969
PATARNELLO, S. ; CARNEVALI, P. - "Learning capabilities of boolean networks" - Neural networks from models to applications, L. Personnaz, G. Dreyfus eds., pp. 398-406, IDSET (ESPCI), Paris, 1989
ROSH, E. ; MERVIS, C. - "Family resemblances : studies in the internal structures of categories" - Cognitive Psychology, vol. 6, pp. 573-605, 1975
TRÉMOLIÈRES, R. - "The percolation method for an efficient grouping of data" - Pattern Recognition, vol.11, Nº 4, pp. 255-262, 1979
© "Les sciences de l'information : bibliométrie, scientométrie, infométrie". In Solaris, nº 2, Presses Universitaires de Rennes, 1995